
オリジナルキャラクターや、AI彼氏・AI彼女と音声チャットを楽しみたい、でもCotomoのようなクラウドサービスはプライバシーが心配、という方向けに、全てWindowsローカル環境で動作するシステムをご紹介します。LLMを実行するためのLM Studio、キャラクターの設定を管理するためのSillyTavern、日本語TTSのAivisSpeechを組み合わせています。全て無料で利用できます。
AivisSpeechとSillyTavernを使ったおしゃべりAIシステムの概要
今回のシステムの概要と注意点をご紹介します。
やりたいこと
今回の目的は、自分が作成したオリジナルのAIキャラクターと音声会話をするシステムを、Windowsのローカル環境で動かすことです。
前回、テキストで会話をするところまではできたのですが、音声入出力はできませんでした。
-

SillyTavernを使ってローカル環境で動くAI彼氏・彼女を作る方法
2025/10/9
AI彼氏、AI彼女が欲しい! でも怪しげなサービスやアプリばかりだし、ChatGPTに入力するのはプライバシーが気になる……という方におすすめのツールがSillyTavernです。SillyTaver ...
今回は、キャラクターが自動で喋るところまで実現できました。
ただし、ユーザー側の音声入力には対応していません。
Cotomoではダメなの?
「自分が作成したオリジナルのAIキャラクターと音声会話をするシステム」とは、まさにCotomoが提供しているサービスです。
Cotomoは、キャラクター作成も簡単ですし、無料プランでも時間無制限で利用することができます。
ただやはり、クラウドサービスのため、プライバシーが気になります。
-

おしゃべりAI Cotomoの危険性と、なるべく安全に利用する方法
2025/4/13
Cotomoは、AIと音声会話をすることができるアプリで、無料でも時間無制限で利用できることから人気を集めています。またAIの性格を簡単に設定できるので、自分オリジナルのキャラクターと会話をすることが ...
完全ローカルで実行することができれば、誰の目を気にすることもなく、自由な会話をすることができるようになります。
Cotomoとの違いは、Cotomoは音声入力もできるという点と、動作が圧倒的に速いという点です。
PCのスペック次第ですが、ローカルで実行するとやはり遅くなります。
ローカルでいろいろ動かしすぎなので、LLMのモデルは、小さめにした方がいいかもしれません。
システムの全体像
システムの全体像です。
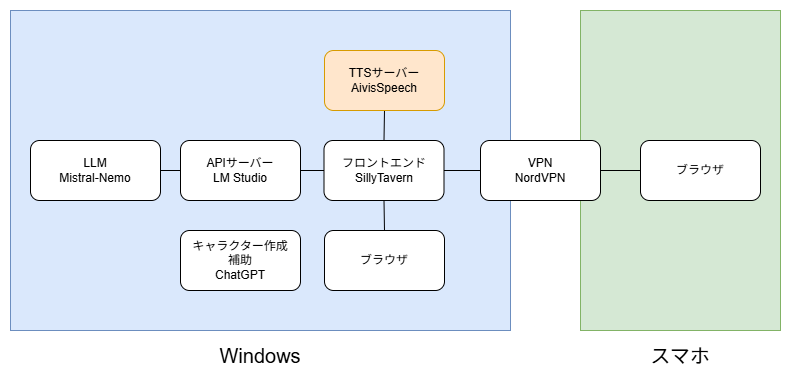
前回のシステムに、TTS(Text To Speech)の「AivisSpeech」が加わりました。
AivisSpeechは、VOICEVOXをもとに開発されたAI合成音声アプリで、無料で使用できます。
AivisSpeechはWindows上で実行でき、APIも提供していますが、SillyTavern側が対応していないことが問題でした。
SillyTavernは主に英語圏(+中国語圏?)で使われており、日本人ユーザーはほとんどいないので、待っていても対応される可能性は低そうです。
無ければ作ればいいじゃない
仕方がないので、自分で作ってみることにしました。
私はプログラマーではありませんが、最近、ChatGPTを使えば素人でもプログラミングができるという話はよく聞きます。
今回の裏テーマは、ノンプログラマーでもChatGPTを使ったらAPI連携できるのか、です。
結論として、2時間でとりあえず動くところまではいけました。
方法の調査も含め、ChatGPTとのやりとりは、7往復です。
他のTTS連携のソースコードを、サンプルとして見せたことが良かったようです。
AivisSpeechの使い方
まずは普通に、AivisSpeech単体で使用する方法をご紹介します。
インストール
「Aivis Project」のページから、「AivisSpeechをダウンロード」をクリックします。
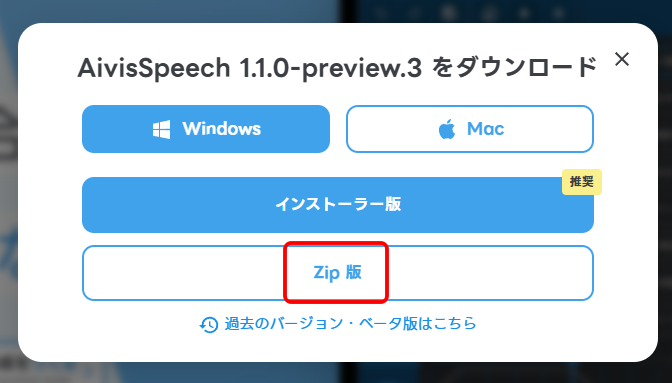
今回は、WindowsのZip版を選択しました。
インストーラー版でもいいと思います。
適当なフォルダに展開します。
「SillyTavern」と同じフォルダとなっていますが、特に意味はありません。
実行
フォルダの中の「AivisSpeech.exe」をダブルクリックして実行します。
ライセンス情報を確認し、「同意してはじめる」をクリックします。
「LGPL-3.0」という、比較的緩いライセンスとなっています。
利用状況のアクセス解析に協力するかの確認です。
どちらでもいいと思いますが、今回はプライバシー保護をテーマとしていますので、「拒否」を選択しました。
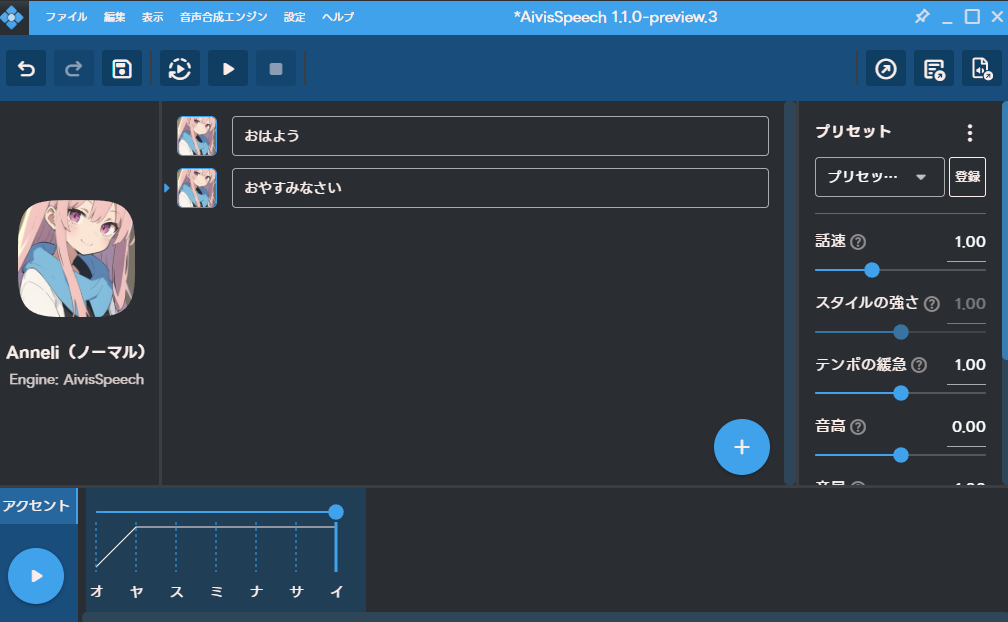
このような画面となれば成功です。
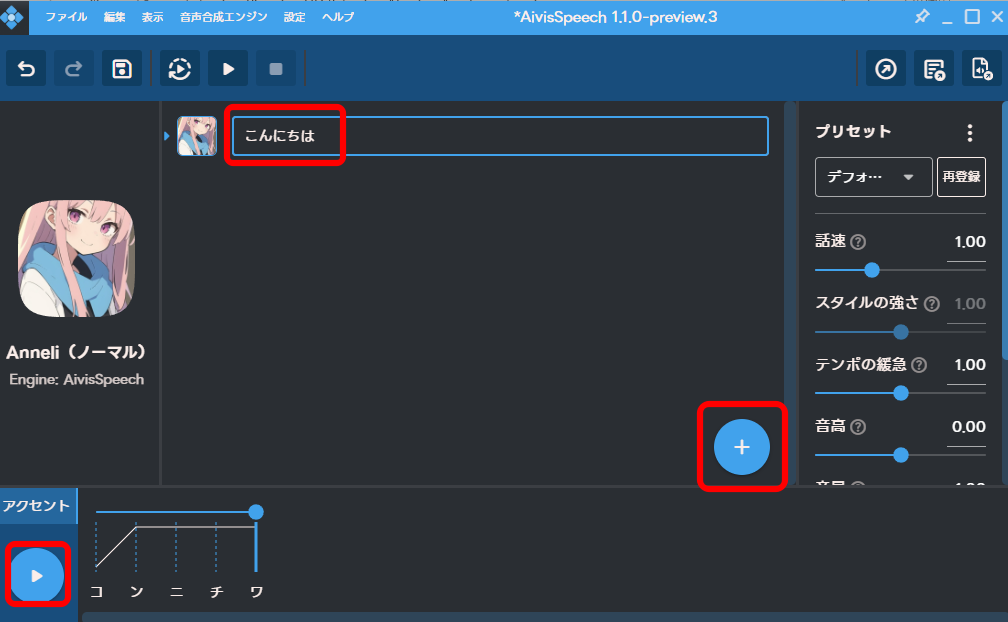
文字を入力し、左下の「▶」をクリックすれば、音声が再生されます。
「+」をクリックすれば、行を追加できます。
音声モデルの追加
音声モデルを追加するには、「設定」-「音声合成モデルの管理」をクリックします。
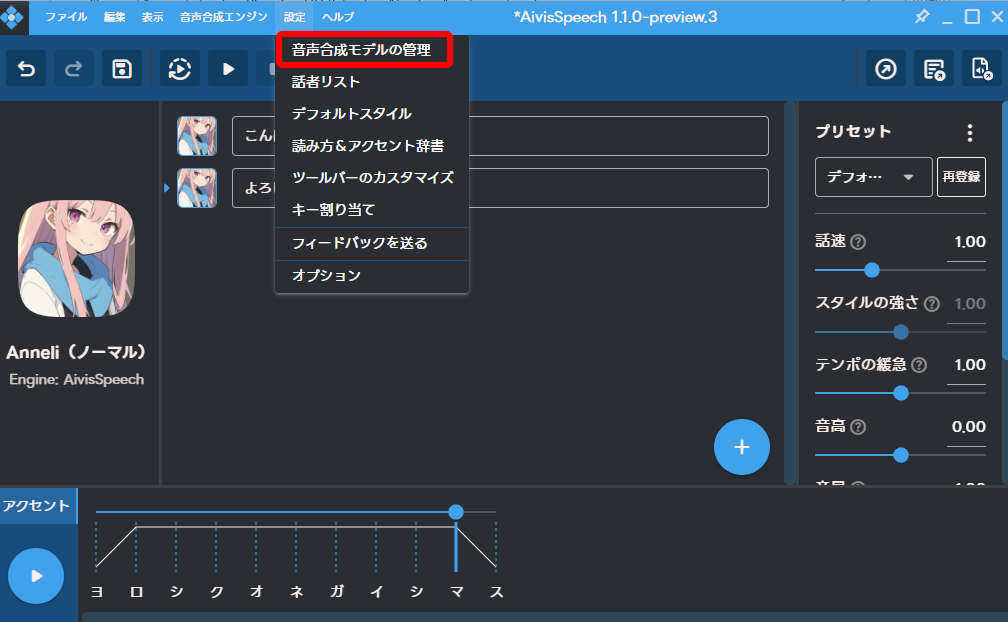
「音声合成モデルを探す」をクリックします。
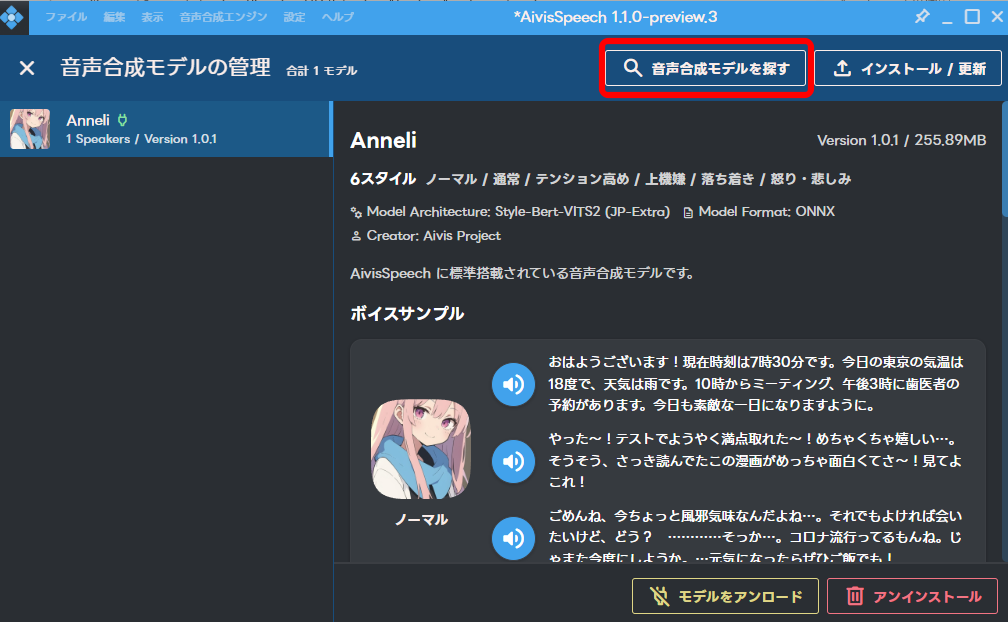
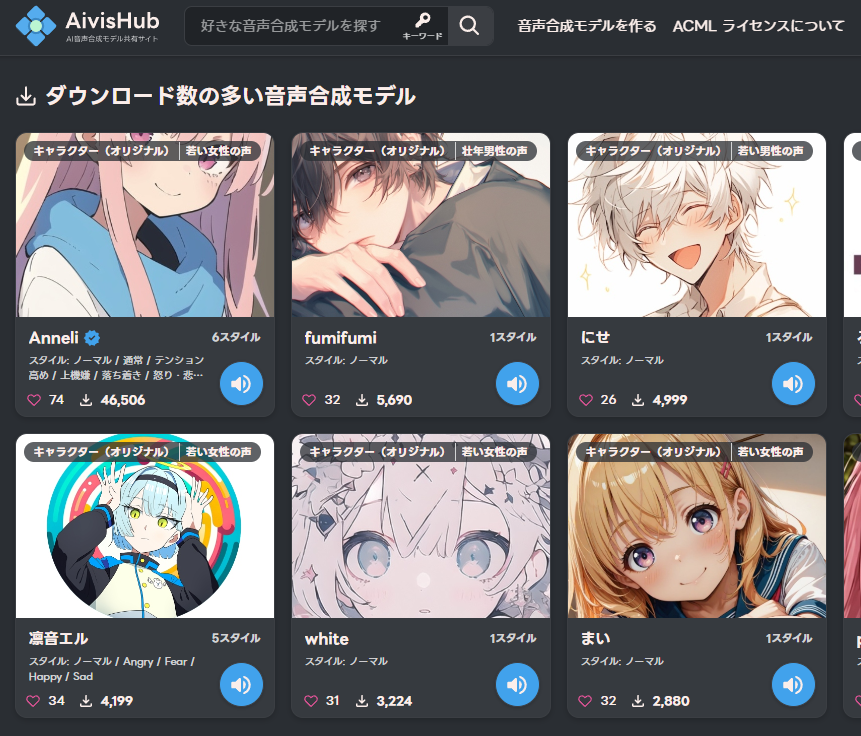
ブラウザで「AivisHub」が開くので、好きなモデルを選びます。
「ダウンロード」をクリックします。
(AivisSpeechに直接取り込む方法は、開発中とのことです)
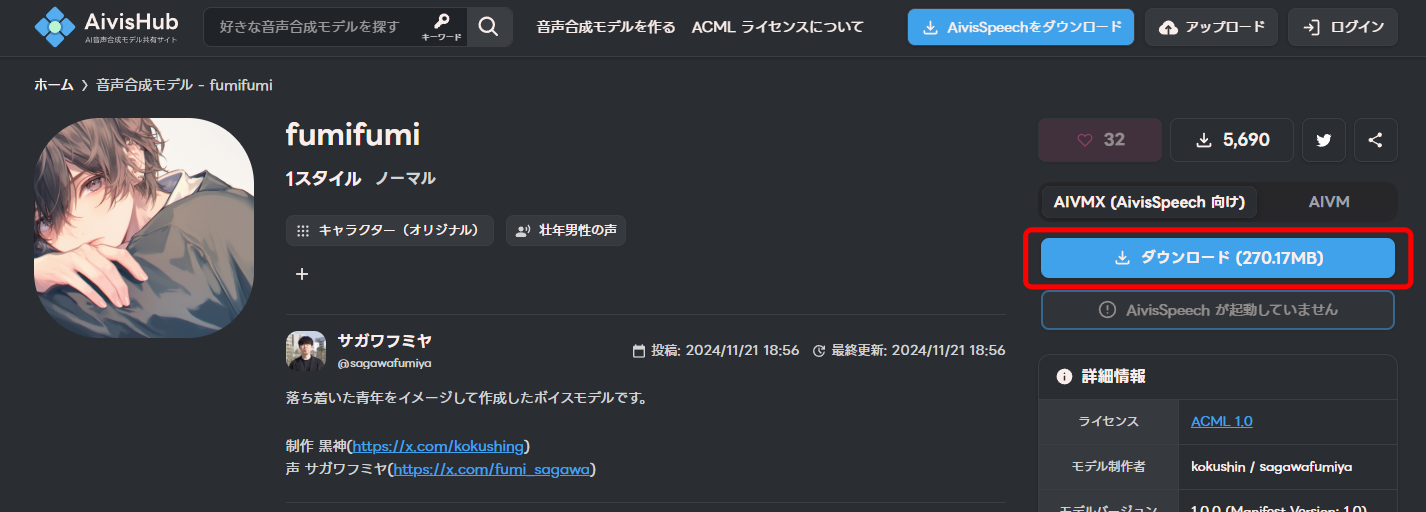
「インストール / 更新」から、ダウンロードした「.aivmx」ファイルを選択し、インストールします。
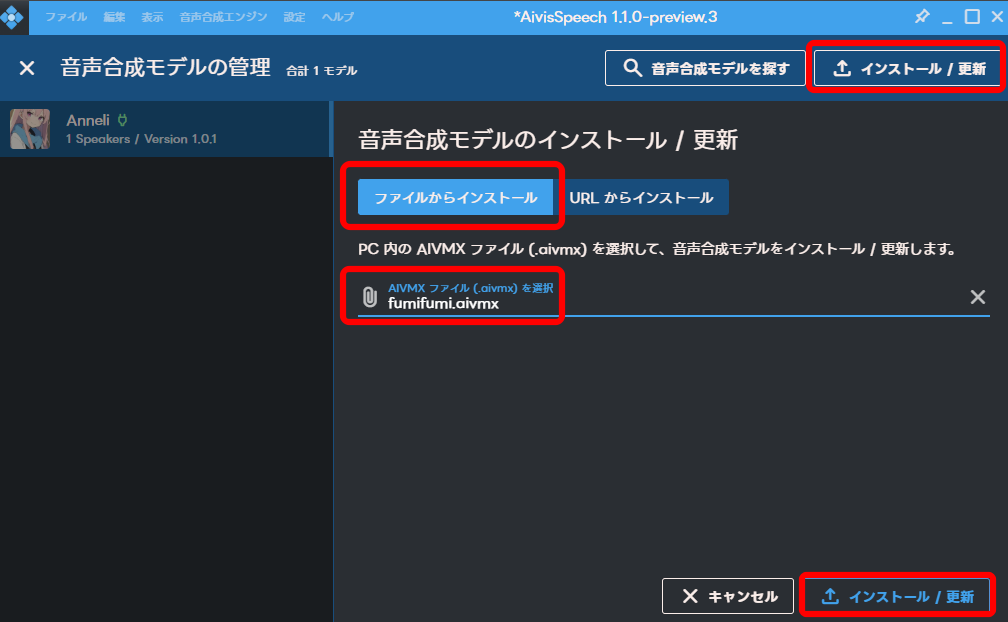
「閉じる」をクリックします。
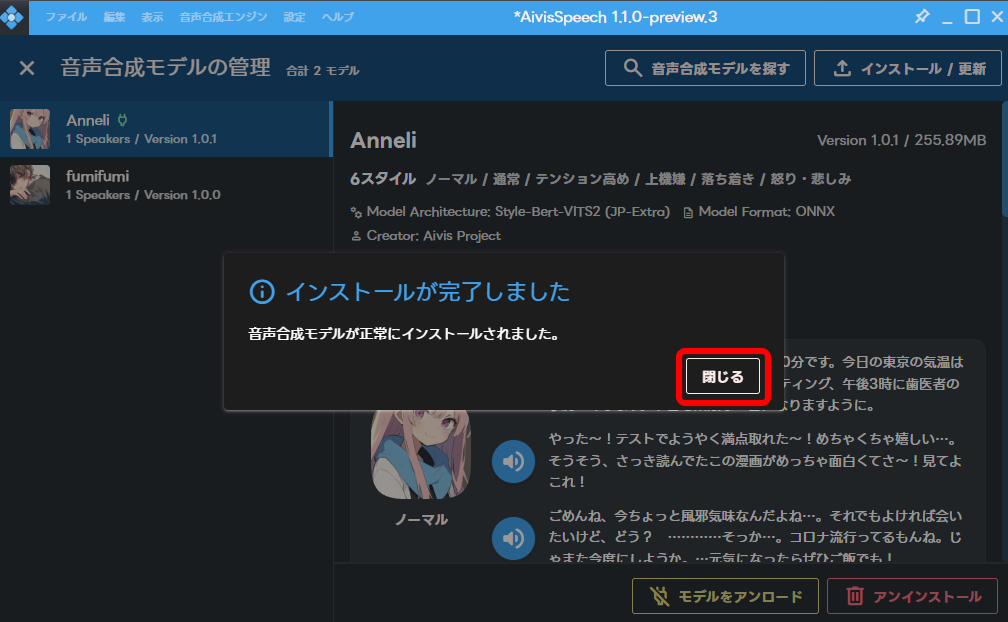
「モデルをロード」をクリックします。
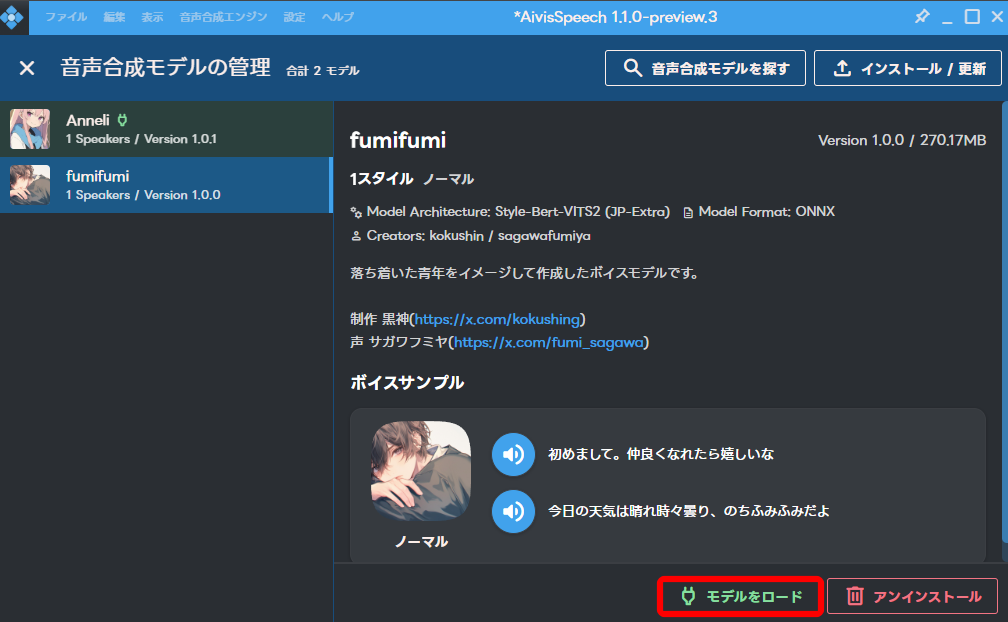
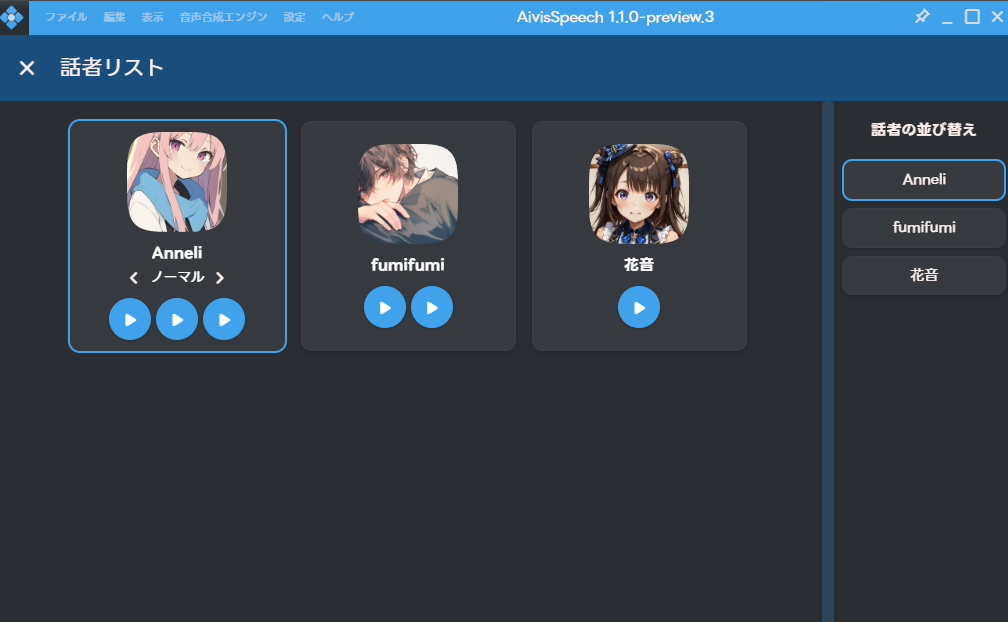
モデルを切り替えることができるようになりました。
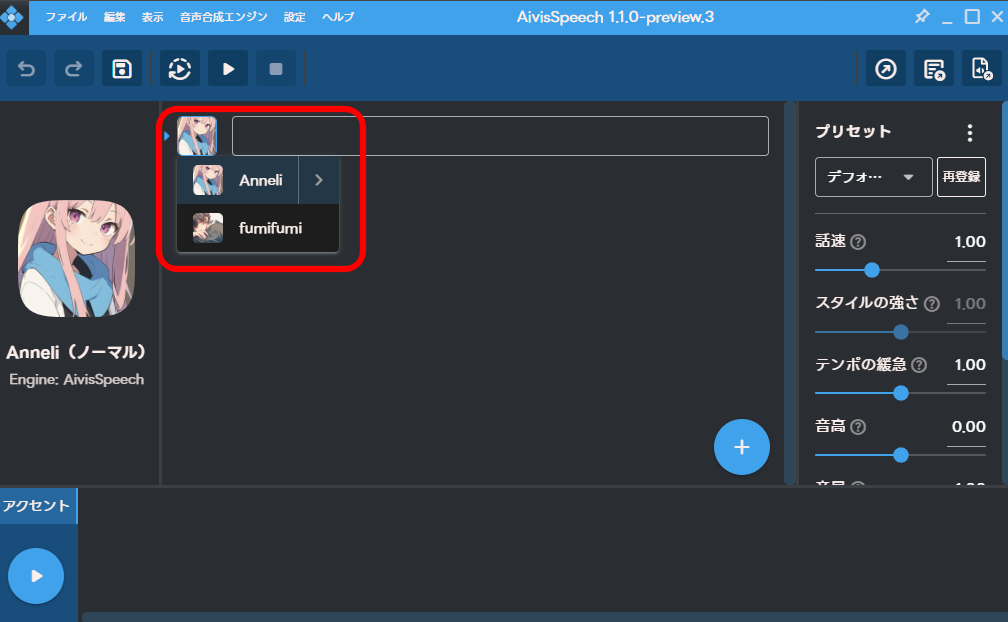
オリジナルモデルの作成
公開されているモデルではなく、自分でモデルを作成したいという場合は、以下の記事をご参照ください。
-

5秒の音声データからAI音声を生成できるGPT-SoVITSの使い方
2025/5/30
GPT-SoVITSは、数秒程度の音声サンプルから、似た声の音声を生成できるTTSです。これにより、自分の声や、好きな声を使って、AIボイスを簡単に生成することができます。この記事では、Windows ...
アクセントの調整
AvisSpeechでは、アクセントも簡単に調整することができます。
しかし、日本語アクセント(東京アクセント≒標準語)の基本ルールを分かっていることが前提なので、簡単にご紹介します。
- 高い音(H)と低い音(L)がある
- 1拍目と2拍目の音の高さは異なる(HLまたはLH、ただし例外多数)
- 単語内で、1回のみHからLに下がることがある(下がらないこともある)
- 一度下がったLは、その単語内でHに上がらない(最初以外は下がるのみ)
例として、「彼氏」は標準語では「HLL」となっています。
しかし日常会話では「LHH」と発音されることも多いので、これを辞書登録してみたいと思います。
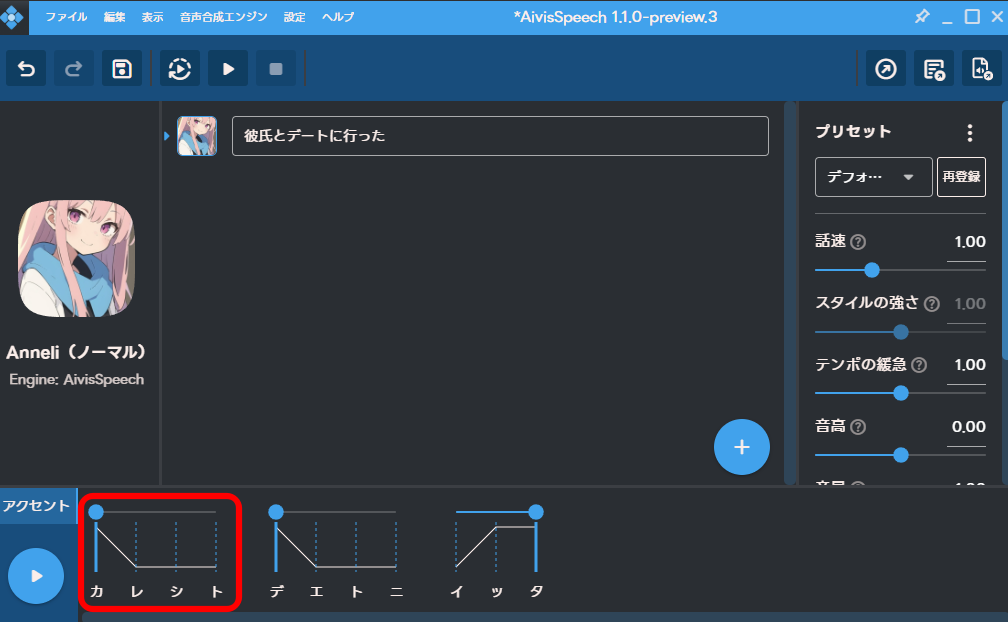
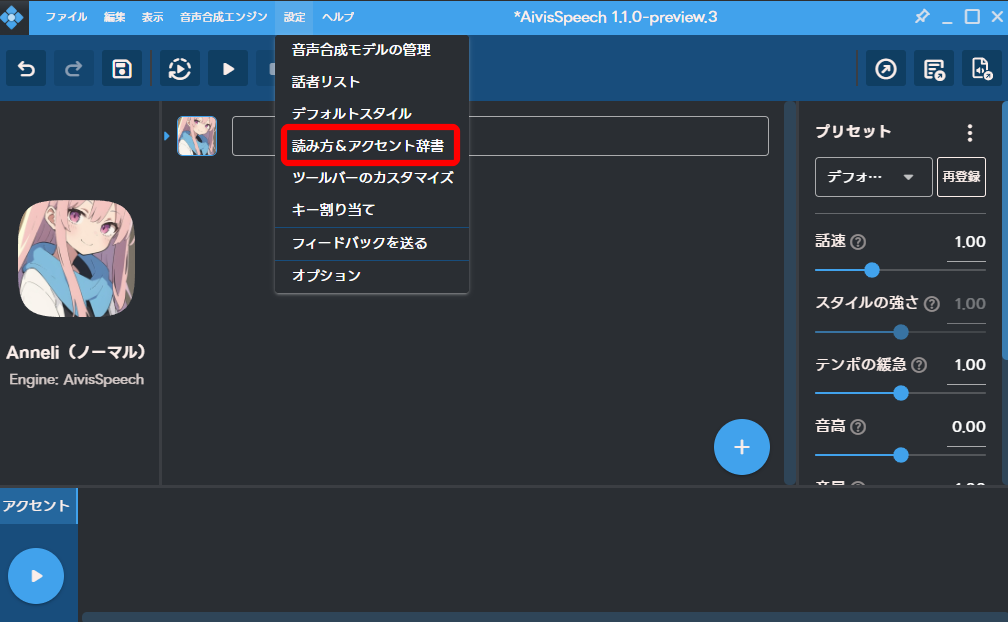
「設定」から「読み方&アクセント辞書」をクリックします。
右上の「追加」をクリックします。
「担々麺」はサンプルとして登録されているものです。
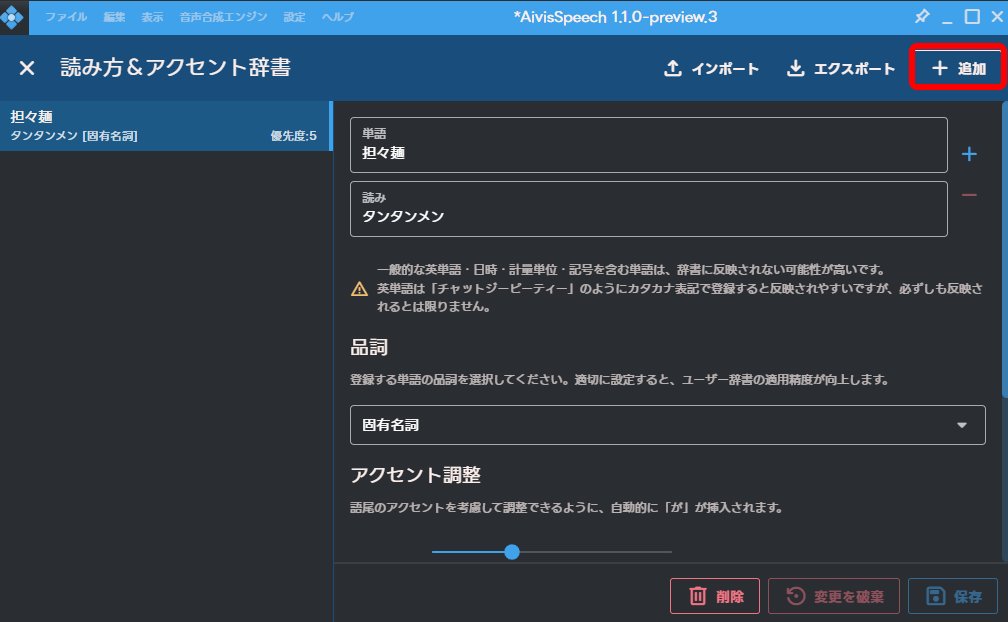
読み方と品詞を登録します。
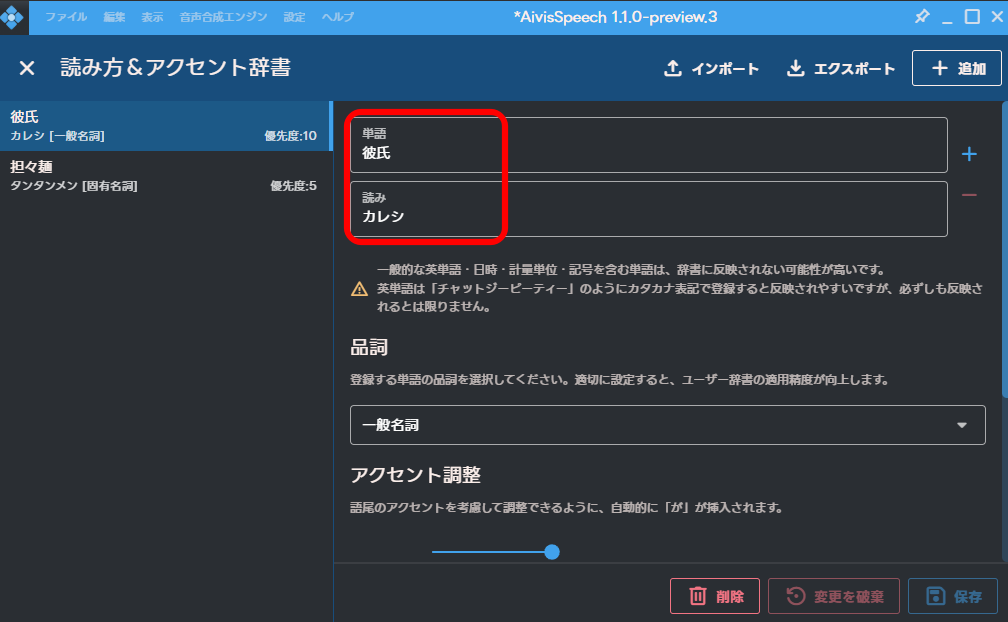
アクセント位置を調整します。
ルール2の「1拍目と2拍目の音の高さは異なる」の例外を無視して、必ず異なるものとすれば、どの位置で音が下がるかだけを決めればよいことになり、仕組みを簡素化できます。
しかしこの方法では、1拍目と2拍目が同じ高さの例外は表現できないことになります。
例えば「東京都(トウキョウト)」は、教科書的には「LHHHL」ですが、実際には「HHHHL」と発音されることが多いです。
このようなパターンを辞書登録することはできません。
ただ、表記上そのような制約があるだけで、生成される音声は必ずしもそれに従っているわけでもないようです。
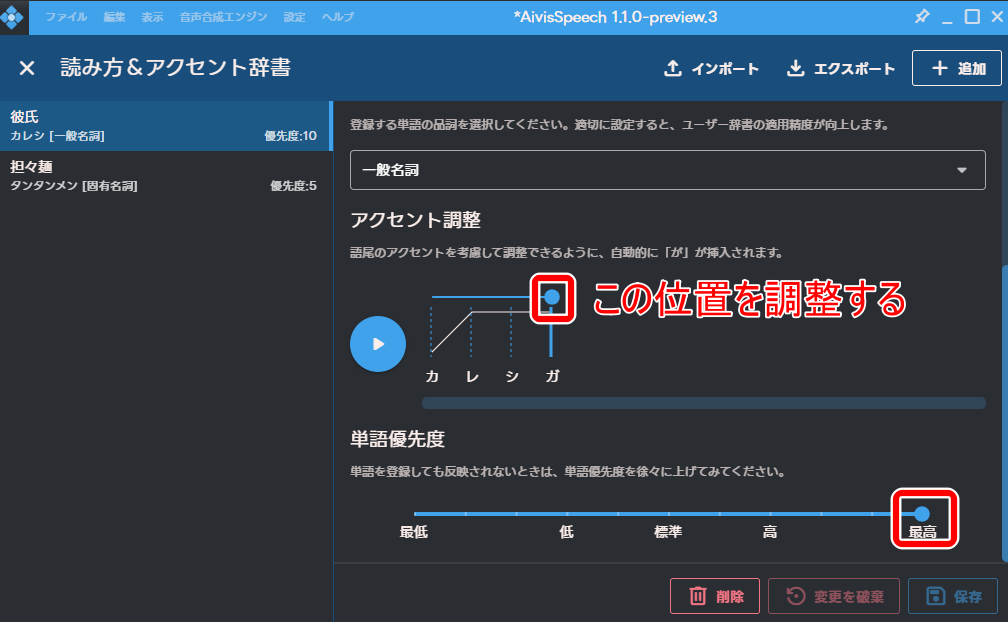
また、辞書登録をしてもアクセントが反映されないことがあります。
その場合は、優先度を調整します。
「彼氏」は、標準では反映されなかったので、最高にしたところ反映されました。
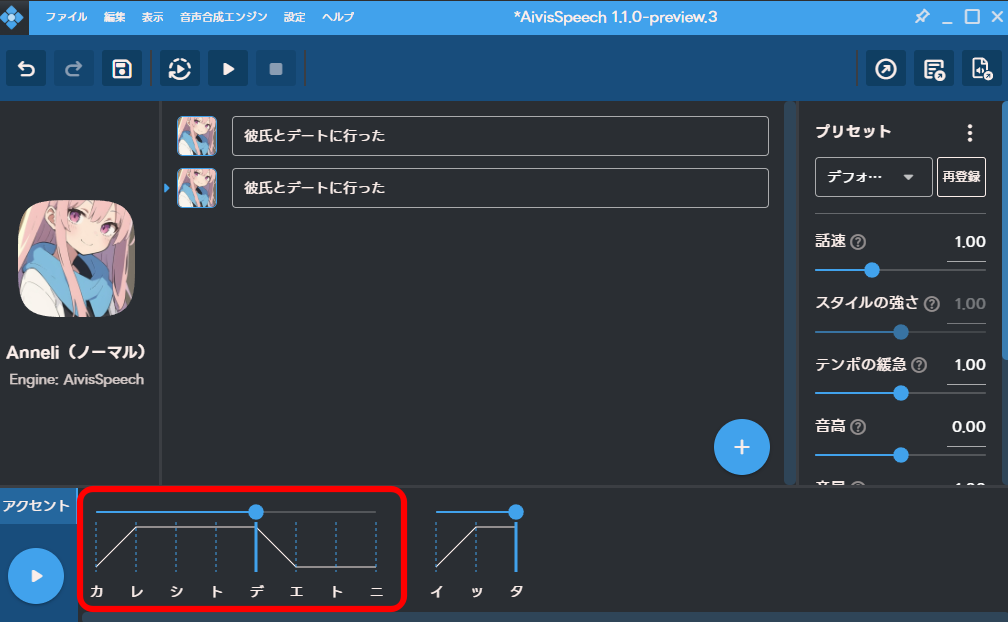
「行った」も音の高さが同じパターンを表記できないという仕様上の制限であり、実際に生成されている発音とは異なる気がします。
ここで登録した辞書は、下記でご紹介するSillyTavernからの呼び出し時にも反映されます。
サーバーの確認
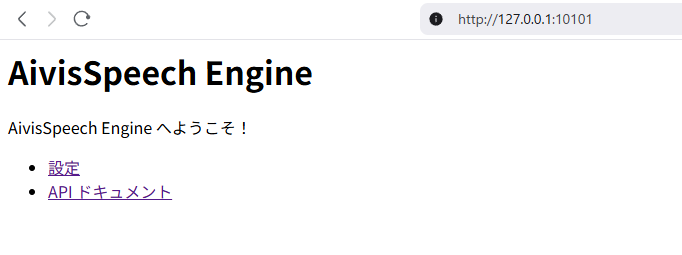
AivisSpeechアプリを起動すれば、サーバーも起動しています。
ブラウザで「http://127.0.0.1:10101/」を開き、以下のような画面が表示されることを確認してください。
AivisSpeechとSillyTavernの連携
SillyTavernからAivisSpeechのAPIを呼び出す方法、スマホからアクセスする方法をご紹介します。
注意点
SillyTavernの環境構築が済んでいない方は、下記の記事をご参照ください。
-
SillyTavernを使ってローカル環境で動くAI彼氏・彼女を作る方法
2025/10/9
AI彼氏、AI彼女が欲しい! でも怪しげなサービスやアプリばかりだし、ChatGPTに入力するのはプライバシーが気になる……という方におすすめのツールがSillyTavernです。SillyTaver ...
SillyTavernには最初から、TTSと連携する設定項目がありますが、AivisSpeechには対応していません。
今回は、その連携部分を作ることが目的です。
AI生成100%
下記でご紹介するコードは、コメントも含め、ほぼ100%ChatGPTが生成したものです。
動作を保証するものではありませんので、ご了承ください。
自己責任でお願いします。
本体を直接編集
本来であれば、ユーザー拡張機能として追加するべきだと思うのですが、どうやら拡張機能は、GitHub経由でしかインストールできないようです。
そこまでする気はないため、SillyTavern本体を直接編集する方法をとっています。
推奨される方法ではないと思います。
エンジニアの方へお願い
できましたら内容を確認の上、拡張機能として正しい形で公開していただけますと幸いです。
Mikajlo氏が作ってくださいました。ありがとうございます!
拡張機能での追加(推奨)
AI生成したコードを修正の上、GitHubに公開していただけたので、簡単にインストールできるようになりました。
「Extensions」アイコンから、「Install extension」をクリックします。
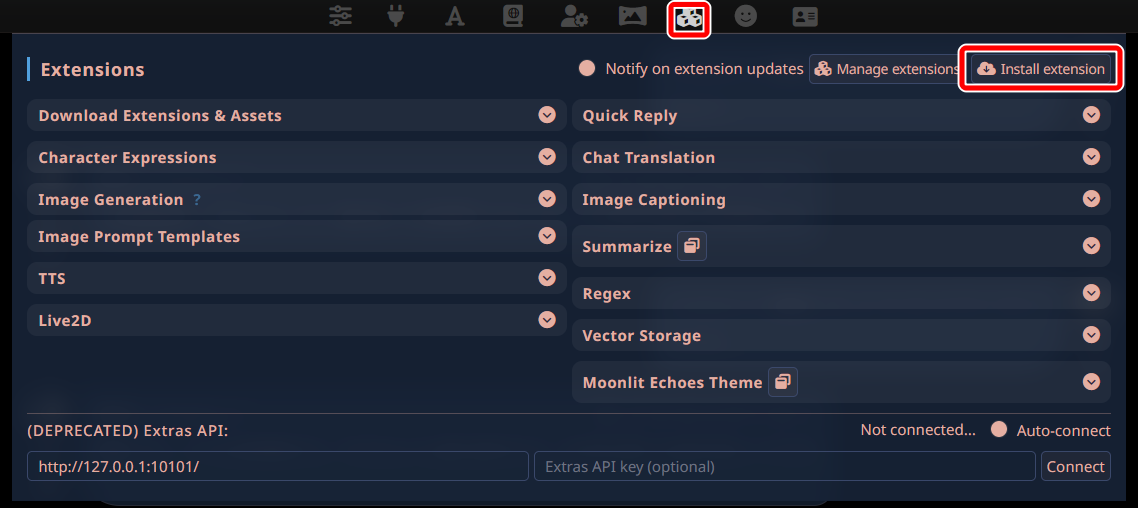
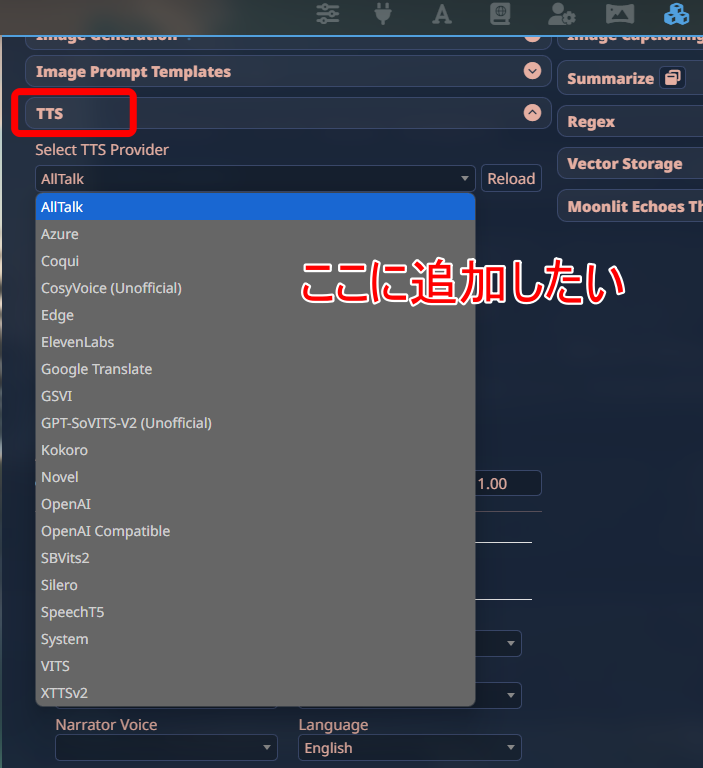
「https://github.com/kotwys/AivisSpeech-SillyTavern」を入力し、「Install for all users」をクリックします。
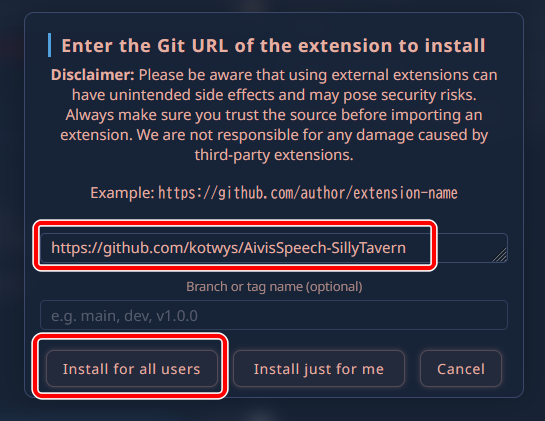
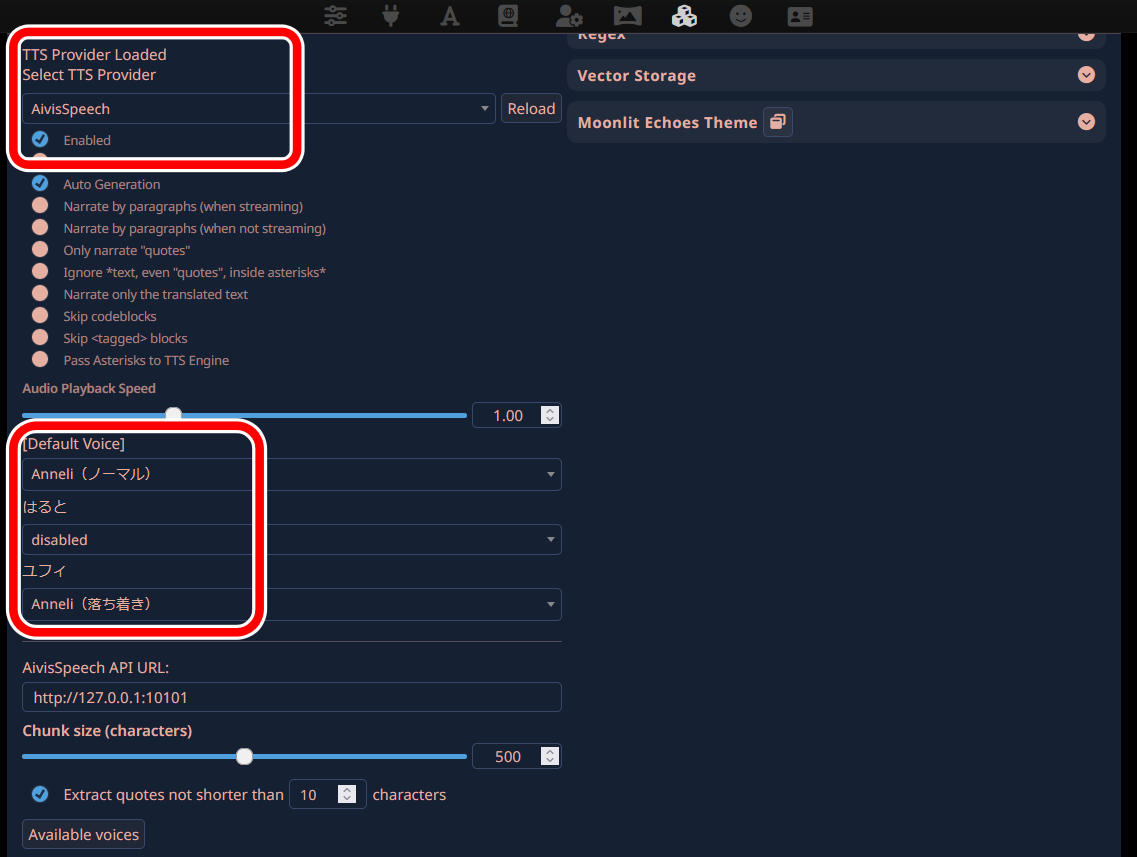
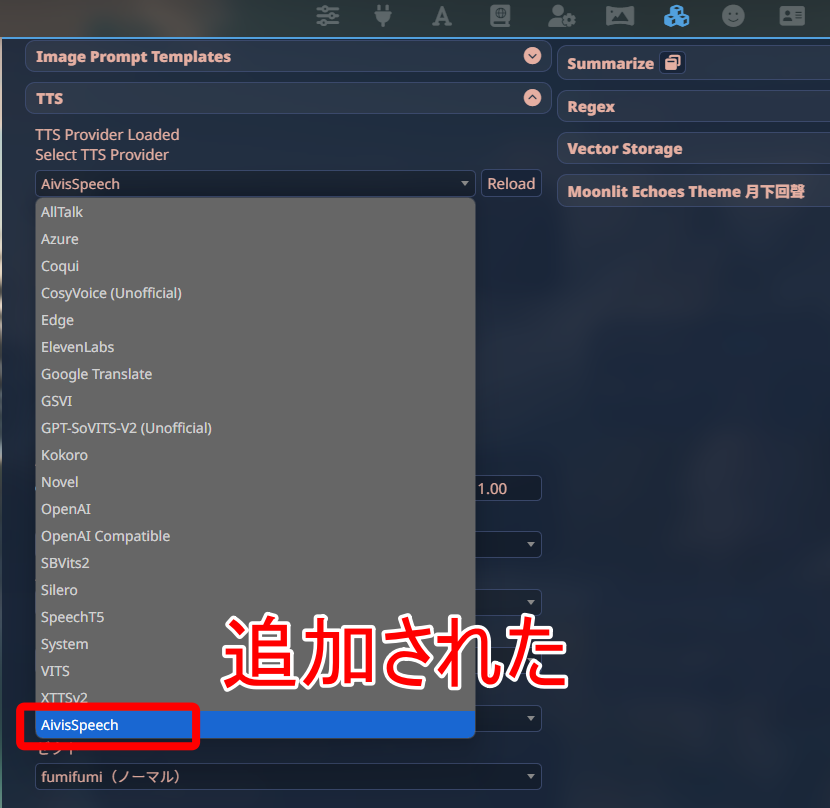
TTS Providerに「AivisSpeech」が追加されました。
「Enabled」にチェックを入れ、キャラクターごとに音声を選択すれば、自動的に喋るようになります。
キャラクターが表示されていない場合は、一度チャット画面を開いてください。
手動での登録(非推奨)
以前のやり方です。一応残しておきます。
aivis.jsの作成
下記の内容をコピーし、「aivis.js」として保存します。
aivis.js(クリックして展開)
export { AivisSpeechTtsProvider };
class AivisSpeechTtsProvider {
settings;
voices = [];
separator = ' 。 ';
defaultSettings = {
baseUrl: 'http://127.0.0.1:10101',
speakerId: '0',
voiceMap: {}
};
get settingsHtml() {
return `
<div>
<label for="aivis_base_url">AivisSpeech Base URL:</label>
<input id="aivis_base_url" type="text" value="${this.settings?.baseUrl || 'http://127.0.0.1:10101'}">
</div>
<div>
<label for="aivis_speaker_id">Speaker:</label>
<select id="aivis_speaker_id"></select>
</div>`;
}
async loadSettings(settings) {
this.settings = { ...this.defaultSettings, ...settings };
$('#aivis_base_url').val(this.settings.baseUrl);
$('#aivis_base_url').on('change', () => {
this.settings.baseUrl = $('#aivis_base_url').val();
this.onSettingsChange();
});
const $select = $('#aivis_speaker_id');
$select.empty();
this.voices = [];
try {
const res = await fetch(`${this.settings.baseUrl}/speakers`);
const speakers = await res.json();
for (const speaker of speakers) {
for (const style of speaker.styles) {
const label = `${speaker.name}(${style.name})`;
const id = style.id.toString();
this.voices.push({
voice_id: id,
name: label,
lang: 'ja-JP',
preview_url: null // プレビュー音声なし
});
$select.append(new Option(label, id));
}
}
} catch (err) {
console.error('[AivisSpeech] スピーカー取得失敗:', err);
toastr.error('話者リストの取得に失敗しました');
}
$select.val(this.settings.speakerId);
$select.on('change', () => {
this.settings.speakerId = $select.val();
this.onSettingsChange();
});
}
onSettingsChange() {
import('./index.js').then(mod => mod.saveTtsProviderSettings());
}
async checkReady() {
const res = await fetch(`${this.settings.baseUrl}/speakers`);
if (!res.ok) throw new Error('AivisSpeech に接続できません');
}
async onRefreshClick() {
return;
}
async fetchTtsVoiceObjects() {
return this.voices;
}
async getVoice(voiceId) {
const match = this.voices.find(v =>
v.voice_id == voiceId || v.name == voiceId
);
if (!match) {
console.error(`[AivisSpeech] 指定された voice_id "${voiceId}" に一致するボイスが見つかりません`);
console.log('現在のvoice一覧:', this.voices);
throw new Error(`voice_id "${voiceId}" not found`);
}
return match;
}
async generateTts(text, voiceId) {
const speaker = parseInt(voiceId ?? this.settings.speakerId);
try {
const queryRes = await fetch(`${this.settings.baseUrl}/audio_query?text=${encodeURIComponent(text)}&speaker=${speaker}`, {
method: 'POST'
});
const query = await queryRes.json();
const synthRes = await fetch(`${this.settings.baseUrl}/synthesis?speaker=${speaker}`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(query)
});
if (!synthRes.ok) {
throw new Error(`音声合成に失敗しました: ${synthRes.statusText}`);
}
return synthRes;
} catch (err) {
console.error('[AivisSpeech] 音声生成中のエラー:', err);
throw err;
}
}
async previewTtsVoice(voiceId) {
toastr.info('このボイスにはプレビュー音声が設定されていません。');
return;
}
}それを「SillyTavern\public\scripts\extensions\tts」フォルダに置きます。
index.jsの編集
同じフォルダにある「index.js」をメモ帳で開きます。
冒頭に以下の行を追加します。
import { AivisSpeechTtsProvider } from './aivis.js';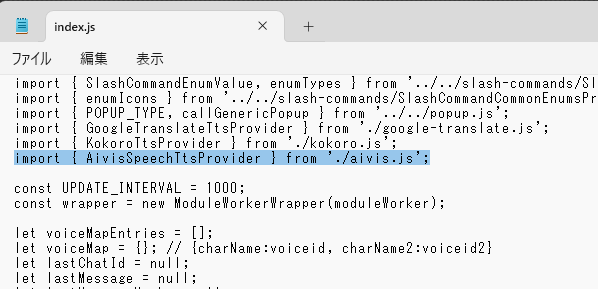
「const ttsProviders」に以下の行を追加します。
AivisSpeech: AivisSpeechTtsProvider,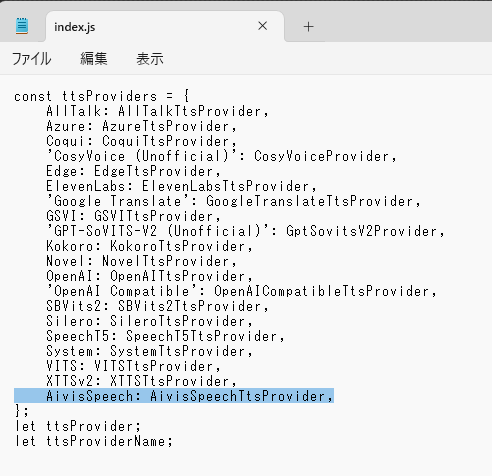
ボイスの選択
SillyTavernを再起動すると、「TTS Provider」に「AivisSpeech」が追加されています。
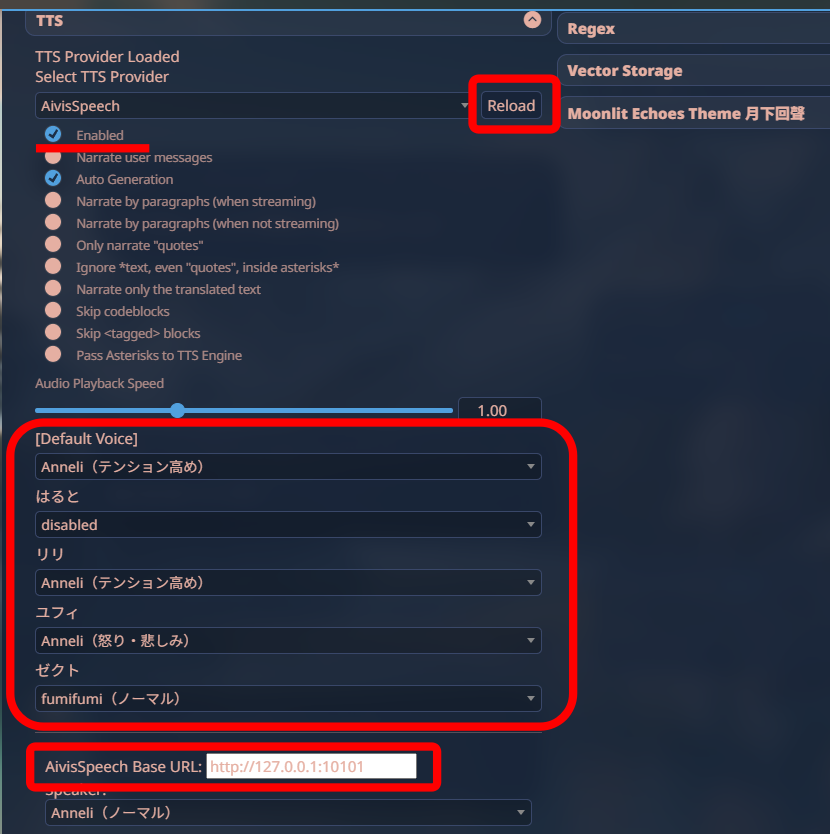
画面下部の「Base URL」が正しいことを確認します。
「Reload」をクリックした後、「Enabled」にチェックを入れます。
キャラクターごとに音声を選択します。
キャラクター一覧は直前のチャットが反映されるので、表示されていない場合は、一度該当キャラクターのチャット画面を開いてください。
これでチャットをすれば、自動的に音声が再生されるようになります。
グループチャットのオートモードで実行すれば、ラジオ代わりにも使えます。
スマホからのアクセス
前回同様に、NordVPNのメッシュネットワークを使用すれば、スマホからでも音声再生できるようになります。
NordVPNのメッシュネットワーク機能は、2025年12月1日に廃止予定です。Tailscaleの利用をおすすめします。 → 継続となりました![]()
![]()
-

Tailscaleとは何? 普通のVPNとは何が違う?
2024/9/17
一般的にVPNは、単一のゲートウェイに複数のノードが接続する、ハブ型の構成が多いですが、ゲートウェイがボトルネックになったり、単一障害点になったりする問題があります。Tailscaleは、P2Pのメッ ...
まず、AivisSpeechをGUIではなく、コマンドラインで起動するようにします。(PC単体で利用する場合もこの方が速いようです)
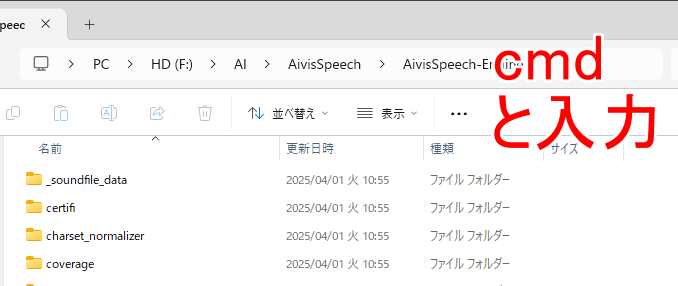
エクスプローラーで「AivisSpeech\AivisSpeech-Engine」フォルダを開き、アドレスバーに「cmd」と入力し、エンターキーを押します。
コマンドプロンプトが開いたら、以下のコマンドを実行します。
オプションは、他のデバイスからのアクセスを許可したり、モデルを事前にロードしたりするためのものです。
run.exe --host 0.0.0.0 --cors_policy_mode all --load_all_models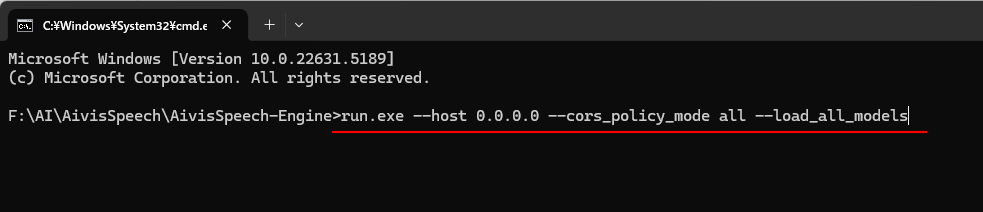
ファイアウォールの確認画面が表示された場合は、「許可」をクリックします。
次はスマホ側の操作です。
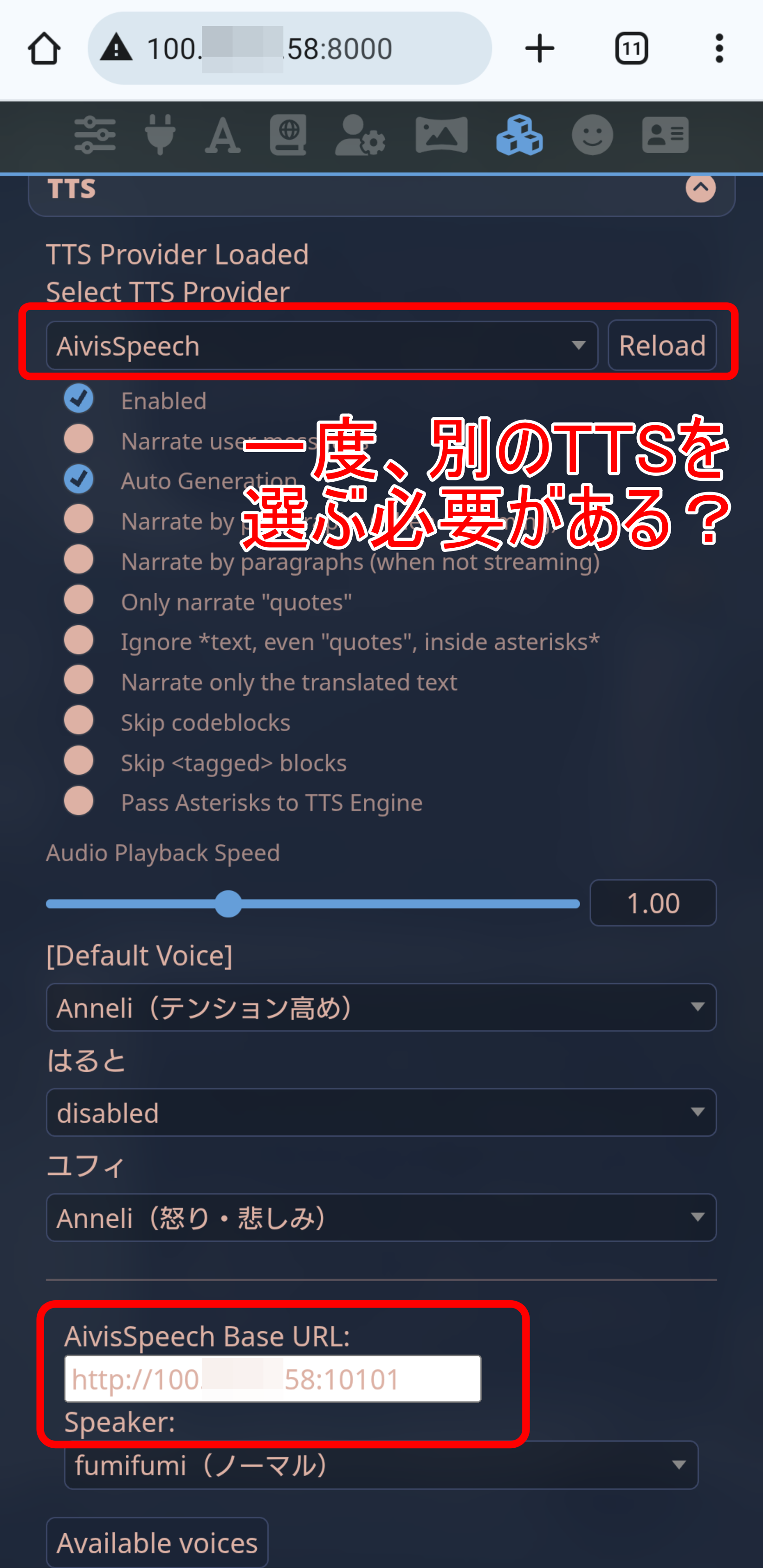
「Base URL」が「127.0.0.1(localhost)」のままでは接続エラーとなるので、NordVPNのメッシュネットワーク上のIPアドレスに変更します。
その上で、一度TTSプロバイダーを他のものに変更してから「AivisSpeech」に戻す必要があるなど、若干動作に不安定なところがあります。
それでも上手くいけば、スマホ本体から音声が再生されるようになります。
AivisSpeechとSillyTavernを使ったおしゃべりAIシステムのまとめ
SillyTavernを使ったオリジナルキャラクターのロールプレイと、TTSのAivisSpeechを組み合わせることで、完全にローカル環境で動作する、AI音声チャットシステムが完成しました。
AI彼氏、AI彼女を作ろうとすると、どうしてもプライバシーが気になりますが、この方法であれば誰にも見られることはありません。
多少大変ではありますが、やる価値はあると思います。
音声入力はまだですが、そこまでニーズはないと思いますので、いったんここまででもいいかなと思っています。
どちらかというと、自分の声をベースに合成音声モデルを作成するというニーズの方があるようです。
今回の副産物として、ChatGPTを利用したプログラミングにも始めて挑戦しましたが、思いの外簡単にできました。
ただし素人が無理やりやった感はありますので、詳しい方が引き継いでいただけますと幸いです。

