
GPT-SoVITSは、数秒程度の音声サンプルから、似た声の音声を生成できるTTSです。これにより、自分の声や、好きな声を使って、AIボイスを簡単に生成することができます。この記事では、Windowsのローカル環境でGPT-SoVITSを実行する方法をご紹介します。
GPT-SoVITSとは
GPT-SoVITSの機能と特徴、この記事の最終目的についてご紹介します。
GPT-SoVITSの概要
「GPT-SoVITS」とは、音声変換(Voice Conversion、VC)と音声合成(Text-to-Speech、TTS)を組み合わせ、さらにWebUIから使えるようにした、統合ツールです。
簡単に言うと、入力したテキストを好きな声で読み上げさせることができるツールで、日本語にも対応しています。
「GPT」がどのように発音するのかを決めるモデルで、「SoVITS」が音声を生成したり変換したりするモデルです。
オープンソースで開発されており、無料で使用することができます。
ゲーミングPC程度のスペックがあれば、ローカル環境で実行することもできます。
この記事では、Windowsのローカル環境で実行する方法をご紹介しています。
GPT-SoVITSの機能
GPT-SoVITSは、以下のような機能を持っています。
ゼロショットTTS
3~10秒程度の音声サンプルから、似た声の音声を生成できます。
ファインチューニング
1分程度の音声データから、精度を向上させることができます。
音声データ処理
音声分割、ノイズ除去、テキスト変換(ASR)、ラベル付けなどの機能も備えています。
ボイスチェンジャー
今後、実装予定とのことです。
この記事の目的
今回の最終目的は、好きな声で喋るAivisSpeechの音声モデルを作成し、AIチャットシステムのSillyTavernと連携させることです。
この記事では、GPT-SoVITSを利用して、音声モデルの訓練用データを生成するところまでをご紹介しています。
訓練用データの準備をしているだけではありますが、GPT-SoVITS単体で見ても、なかなか面白いと思います。
-


AivisSpeechとSillyTavernを使って、CotomoのようなおしゃべりAIを完全ローカルで実行する方法
2025/10/9 AivisSpeech, AIロールプレイ, AI彼女, AI彼氏, LM Studio, SillyTavern, TTS
オリジナルキャラクターや、AI彼氏・AI彼女と音声チャットを楽しみたい、でもCotomoのようなクラウドサービスはプライバシーが心配、という方向けに、全てWindowsローカル環境で動作するシステムを ...
GPT-SoVITSの使い方
Windowsのローカル環境にGPT-SoVITSをインストールし、数秒のサンプル音声から、AI合成音声を出力するまでをご紹介します。
サンプル音声の準備
まず、3~10秒のwavデータが必要となります。
mp3等は使用できません。
10秒以上の長さでも使用できません。
BGMやノイズが乗っておらず、できるだけ高品質なものが望ましいです。
実はこの後の作業より、サンプル音声データを用意する作業の方が面倒と言えるかもしれません。
ここでは既に準備ができているものとします。
ノイズ除去については、こちらの記事をご参照ください。
-

音声ファイルからBGMやノイズを除去するAudacityとOpenVINOプラグインの使い方
TTSで音声学習をしようとする際、高品質な音声データが必要となりますが、BGMやノイズが入っていたりして、なかなか適切な素材を用意することは大変です。Audacityを使用すれば、完璧ではありませんが ...
Windowsへのインストール
GPT-SoVITSのインストールは、基本的にはcondaやDockerを使うようになっていますが、Windows用のパッケージも用意されています。
しかしGitHubからダウンロードできるパッケージは、少し古いようです。
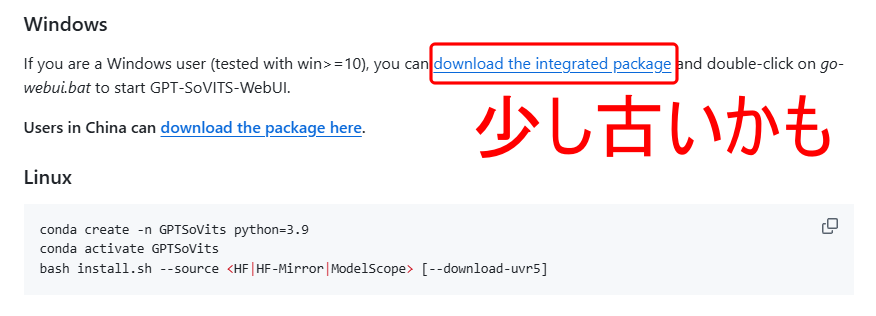
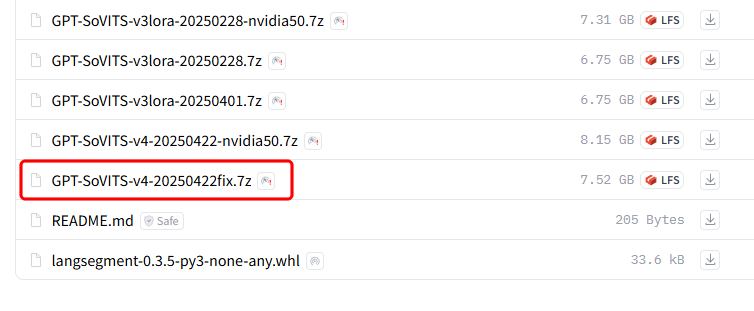
そこで、有志がHuggingFaceで公開している、最新版のパッケージを利用します。
上記ページを開き、最新の日付のもの(ここではGPT-SoVITS-v4-20250422fix.7z)をダウンロードします。
ファイル名に「nvidia50」と付いているものは、NVIDIA GeForce RTX 50xxシリーズに最適化されたものです。
お持ちの方は、そちらを選んでください。
7zで圧縮されているので、7-Zip等を使用して、任意のフォルダに展開をしてください。
必要なものは全て含まれています。
WebUIの起動
ファイルが展開できたら、フォルダの中の「go-webui.bat」をダブルクリックして実行するだけなのですが、このままだと中国語で起動してしまいます。
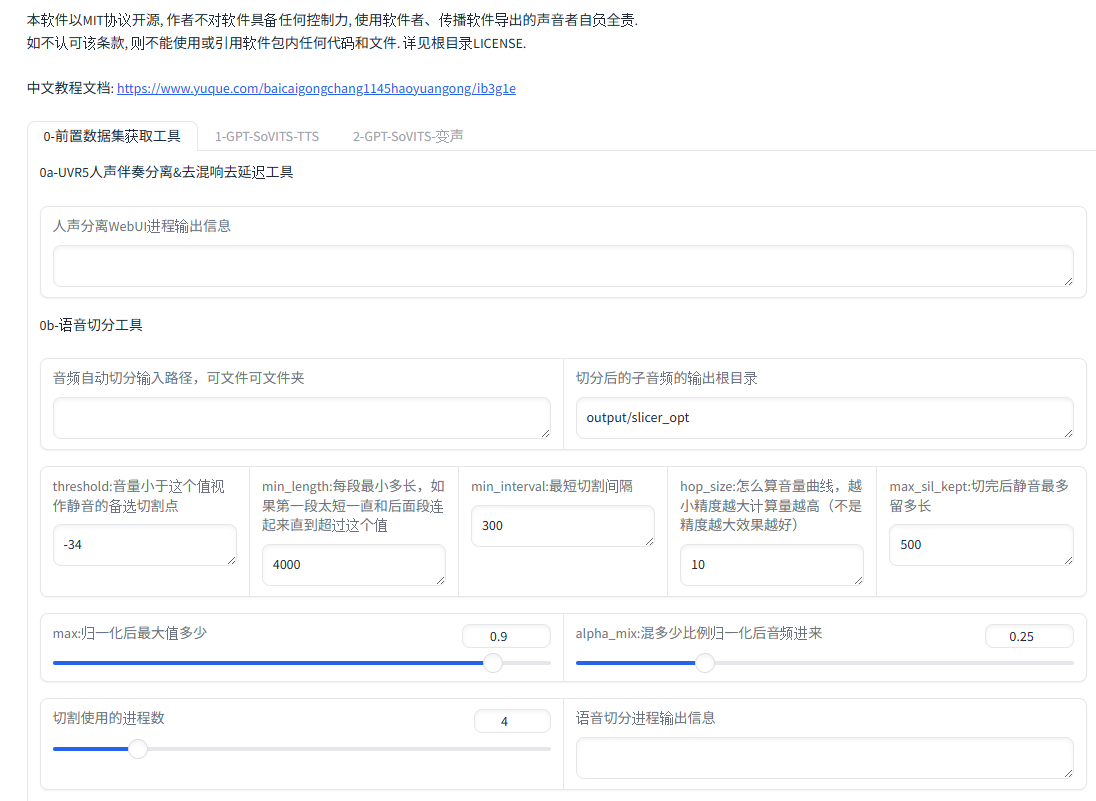
そこでまず、「go-webui.bat」をメモ帳で開きます。
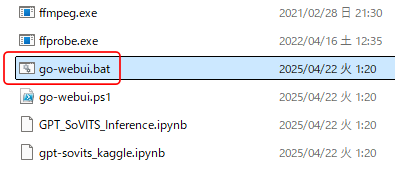
「zh_CN」の文字を削除し、上書き保存します。
消すだけで大丈夫です。
自動的に日本語になります。
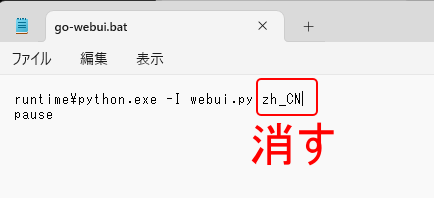
go-webui.batをダブルクリックして実行すると、コマンドプロンプトが開きますので、しばらく待ちます。
起動するまでに、数分かかるかもしれません。
ファイアウォールの警告が表示された場合は、許可します。
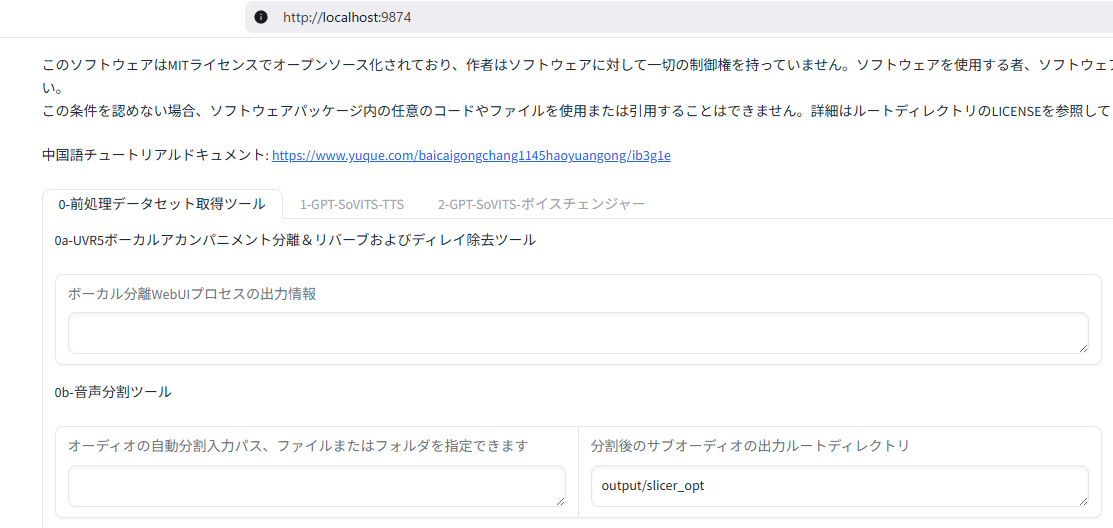
自動的にブラウザで「http://localhost:9874」が開き、以下のような画面となれば成功です。
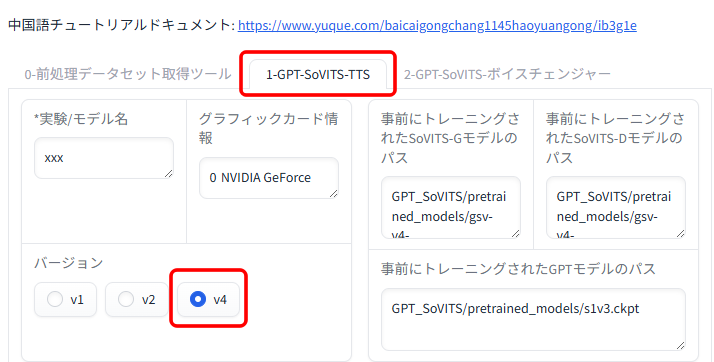
「1-GPT-SoVITS-TTS」タブを選択し、バージョンで「v4」を選択します。
「1C-推論」タブを選択し、「有効化TTS推論WebUI」をクリックします。
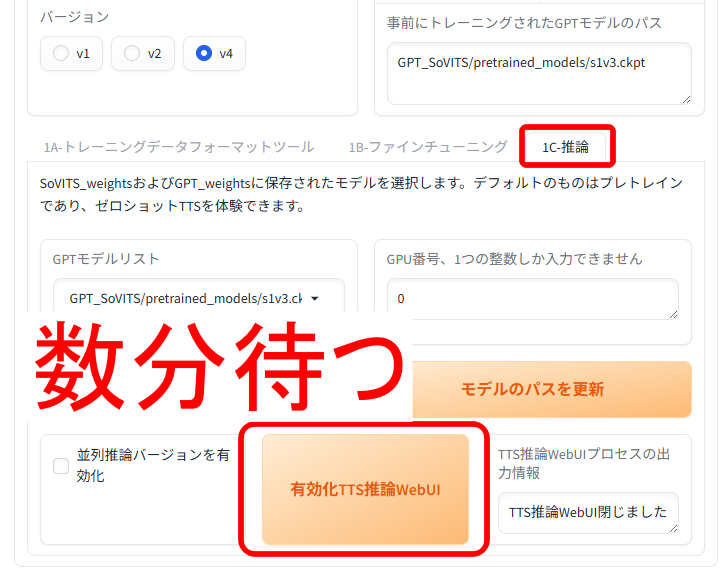
別ウィンドウで「http://localhost:9872/」が開くまで、数分待ちます。
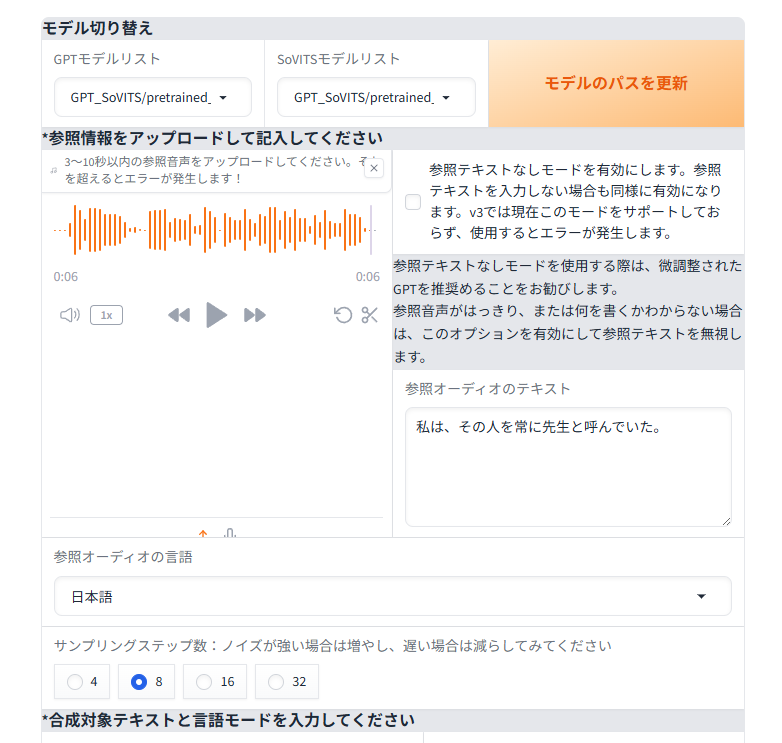
サンプル音声の登録
別ウィンドウが開いたら、用意していたサンプル音声をアップロードします。
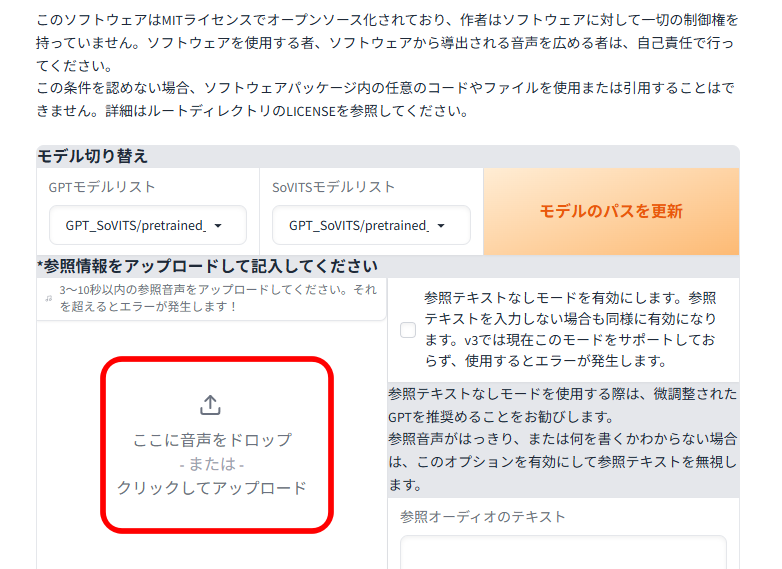
音声のテキストを手入力します。
参照オーディオの言語で「日本語」を選択します。
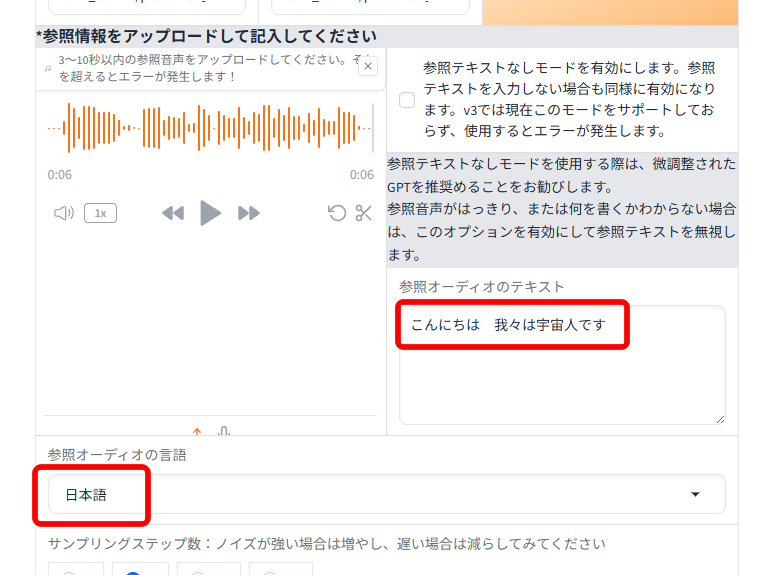
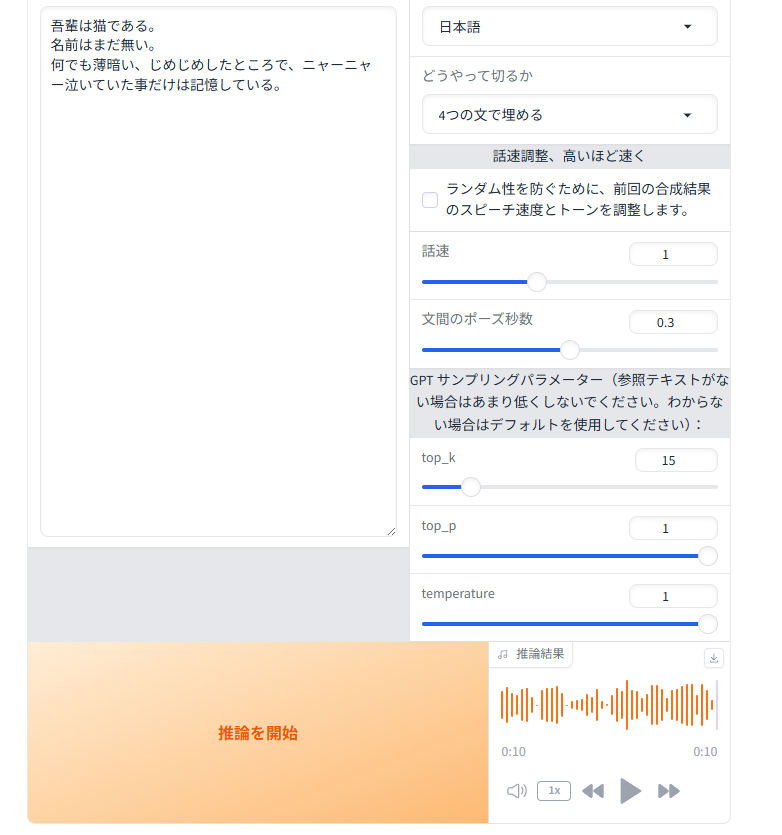
音声生成
以上で準備は整いました。
「推論テキスト」に、喋らせたいテキストを入力します。
「推論の言語対応を減らしたほうが良い」は、「日本語」を選択します。
「推論を開始」をクリックすれば、短いものであれば数秒で音声が生成されます。
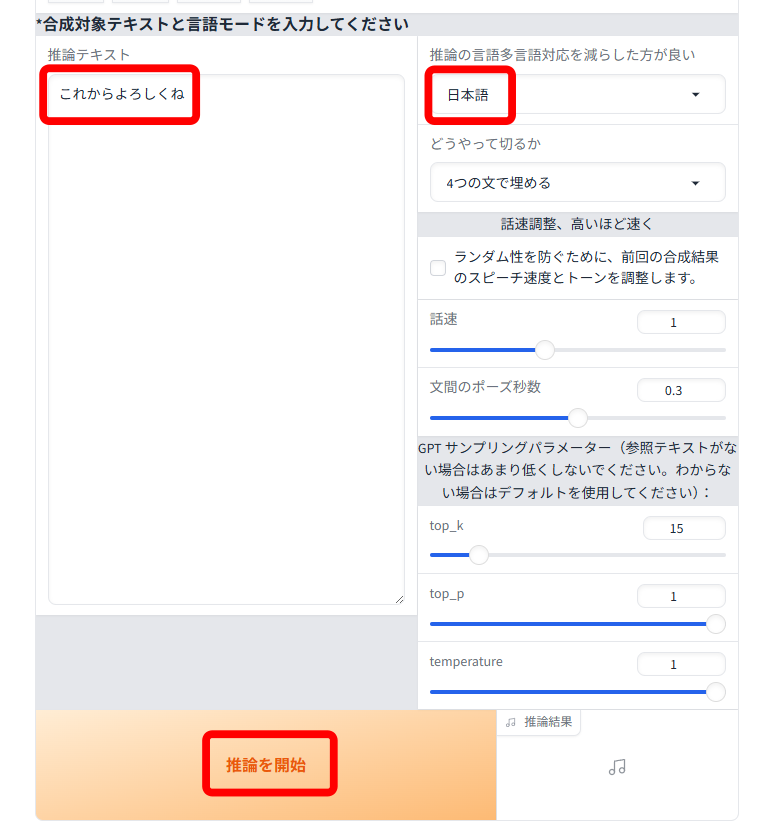
生成される音声は毎回異なるので、何回か試してみて、良い結果だったものをダウンロードしましょう。
今回は単体での利用方法としてご紹介しましたが、次回以降で、音声モデルの訓練用データとして使用したいと思います。
続きは、下記の記事をご参照ください。
-

Style-Bert-VITS2で音声学習し、AivisSpeechのモデルに変換する方法
2025/5/30 AivisSpeech, AI彼女, AI彼氏, TTS
一般的に、好きな声で喋るTTS(Text-to-Speech)モデルを作成するには、学習用データを用意することが大変ですが、Style-Bert-VITS2とGPT-SoVITSを組み合わせれば、数秒 ...
まとめ GPT-SoVITSの使い方とは
GPT-SoVITSは、5秒程度の音声データから、似た声の音声を生成できるTTSです。
Windowsであれば、ファイルを展開するだけで、簡単に使用することができます。
単体で使用しても面白いですが、音声AIモデルの訓練用データを、大量生成するといった使い方もできます。
自分の声を使用するのならばいいのですが、他人の声を使用する場合は、法的に問題がある場合がありますのでご注意ください。

