
Obsidianはテキスト以外のファイルを扱うこともできますが、検索に対応していません。しかし複数のプラグインを組み合わせれば、PDFの中身や、画像検索をすることも可能となります。この記事では、Obsidianのプラグインである「Omnisearch」「Text Extractor」「AI Image Analyzer」の使い方と注意点について解説します。
Obsidianと検索強化/OCR/AI画像認識プラグイン
Obsidian、Omnisearch、Text Extractor、AI Image Analyzerの概要をご紹介します。
Obsidianとは
「Obsidian」とは、ローカル環境で動作するノートアプリです。
全てのノートはMarkdown(.md)形式のテキストファイルとして保存され、Wikiのように双方向でリンクを張ることができます。
コミュニティによるプラグイン開発が盛んで、AI連携も容易であることから、人気が高まっています。
フォルダ管理が容易
私がObsidianで気に入っている点は、システムのフォルダ構造がそのまま引き継がれるという点です。
例えば、以下のような画像フォルダがあったとします。
それをそのままObsidianの保管庫フォルダに移動すれば、自動的に取り込まれます。
インポート/エクスポートのような作業はなく、OSと一体化しているので、とても使いやすいです。
メディア管理は弱い
ただしObsidianは、基本的にはMarkdown形式のテキストファイルを扱うものなので、画像や動画のようなメディアファイルを管理することには不向きです。
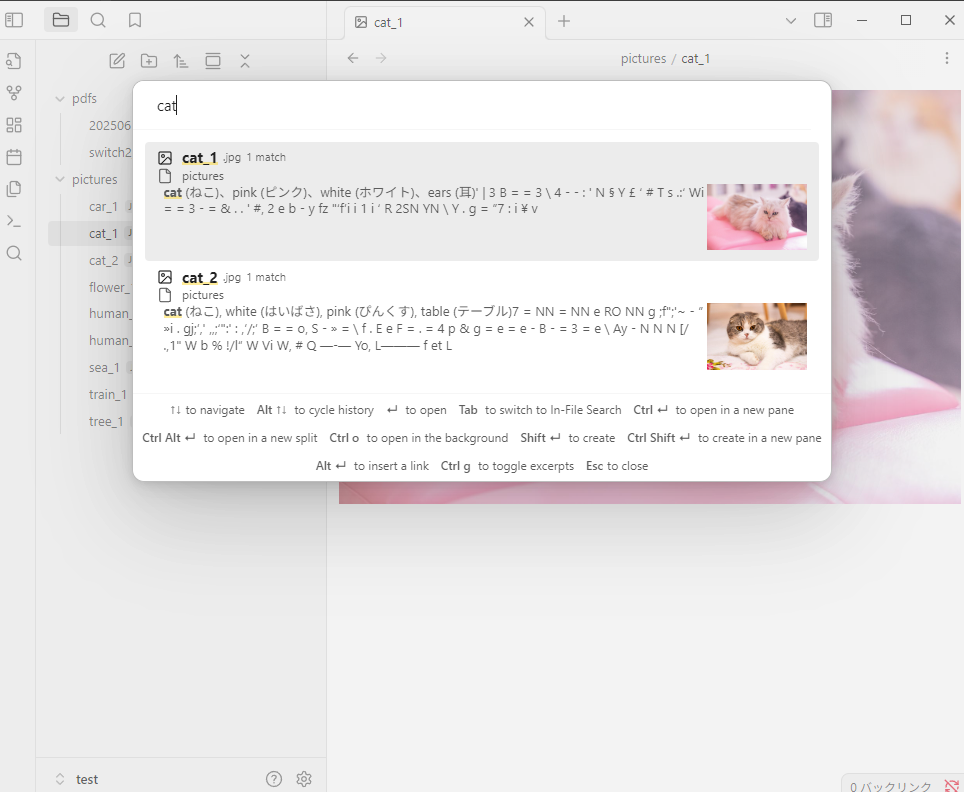
例えば「猫」で検索をしても、上記の画像はヒットしません。(これは通常のOSでも同じですが)
しかし、AIプラグインを組み合わせることで、自動的に画像認識をして、画像検索をすることができるようになります。
Omnisearchプラグインとは
「Omnisearch」は、Obsidianの検索機能を強化するプラグインです。
通常のObsidianの検索機能は、(おそらく)検索インデックスが作成されず全ノートに対して検索処理が走るので、ノート数が数千を超えると、とても遅くなります。
Omnisearchは以下のような機能を持っています。
- 検索インデックスを作成して高速化
- あいまい検索
- 検索ワードの周辺表示
- 検索行に直接ジャンプ
さらに別のプラグイン「Text Extractor」「AI Image Analyzer」と連携することで、PDF検索、画像検索も可能となります。
Text Extractorプラグインとは
「Text Extractor」は、PDFと画像ファイルからテキストを抽出するプラグインです。
PDFファイルからは直接テキストが抽出されますが、画像ファイルに対してはOCRが用いられます。
Omnisearchと連携することで、検出結果をインデックスし、検索対象とすることができます。
AI Image Analyzerプラグインとは
「AI Image Analyzer」は、ローカル環境でAI(LLM)を実行する「Ollama」を使用して、画像解析をするプラグインです。
別途Ollamaがインストールされている必要があります。
Omnisearchと連携することで、解析結果をインデックスし、検索対象とすることができます。
ObsidianのOmnisearchプラグインとPDF/画像検索をする方法
Omnisearch、Text Extractor、AI Image Analyzer、Ollamaのインストールと設定、注意点、使ってみた感想についてご紹介します。
Obsidianのインストール
Obsidianのインストールと、基本的な使い方については、下記の記事をご参照ください。
ここでは、Windows環境での使用を前提としています。
モバイル版アプリは、一部のプラグインが動作しないようです。
-


ノートをリンクでつないで管理できるObsidianの使い方
情報をただ保存するだけでなく、いじくり回しながらアイデアをまとめたいという方に向いているノートアプリがObsidianです。Obsidianは、ノート間のリンクを重視しているので、発想を広げたり、まと ...
Ominisearchプラグインのインストール
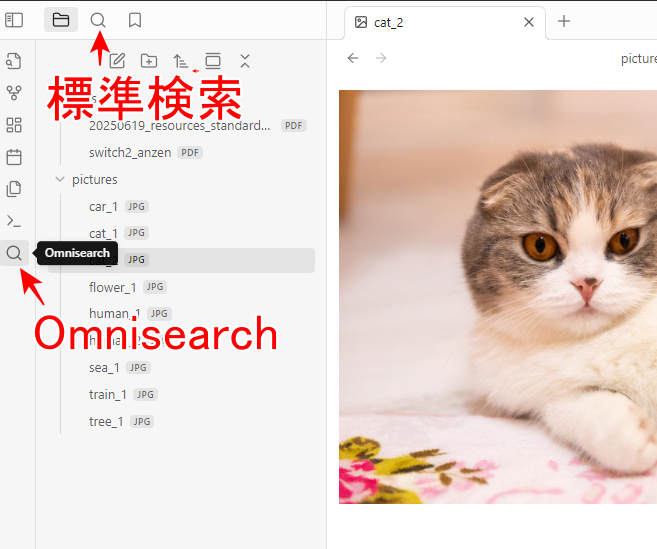
「設定」-「コミュニティプラグイン」から、「Omnisearch」をインストールします。
上部の検索アイコンはObsidian標準のもので、左に表示されている検索アイコンがOmnisearchのものです。
Text Extractorプラグインのインストール
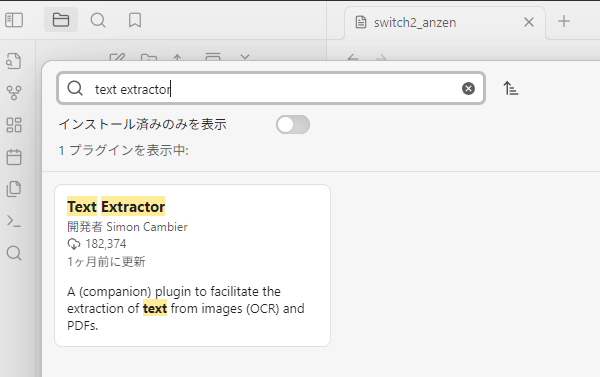
次に「Text Extractor」プラグインをインストールします。
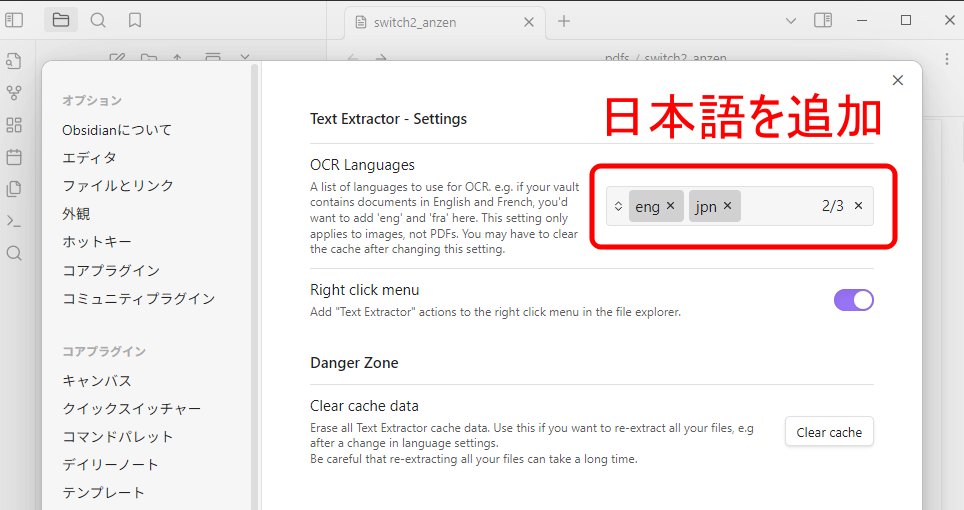
「Text Extractor」の設定画面を開き、「OCR Languages」に「日本語(jpn)」を追加します。
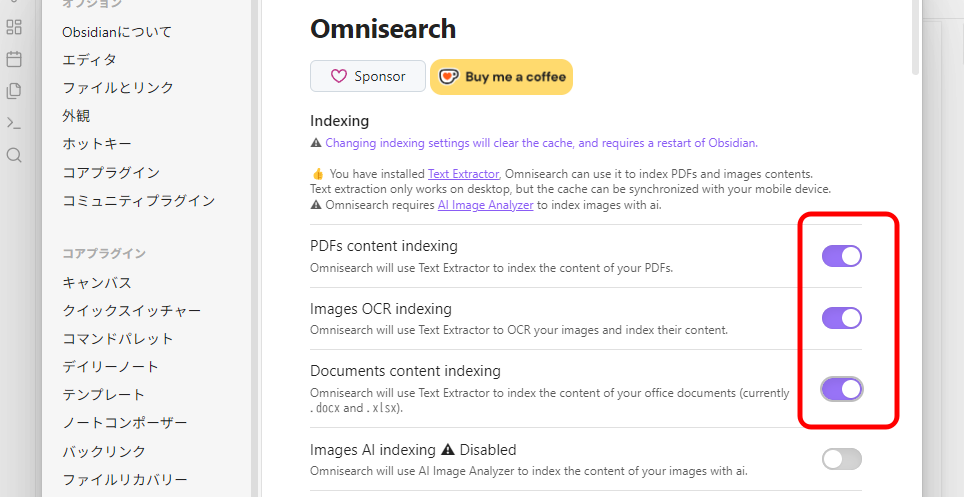
「Omnisearch」の設定画面を開き、「PDFs content indexing」「Image OCR indexing」「Documents content indexing」をオンにします。
その後、Obsidianの再起動が必要となります。
Text Extractorプラグインの使い方
インデックス作成が完了したら、後はOmnisearchで検索をするだけです。
PDF解析
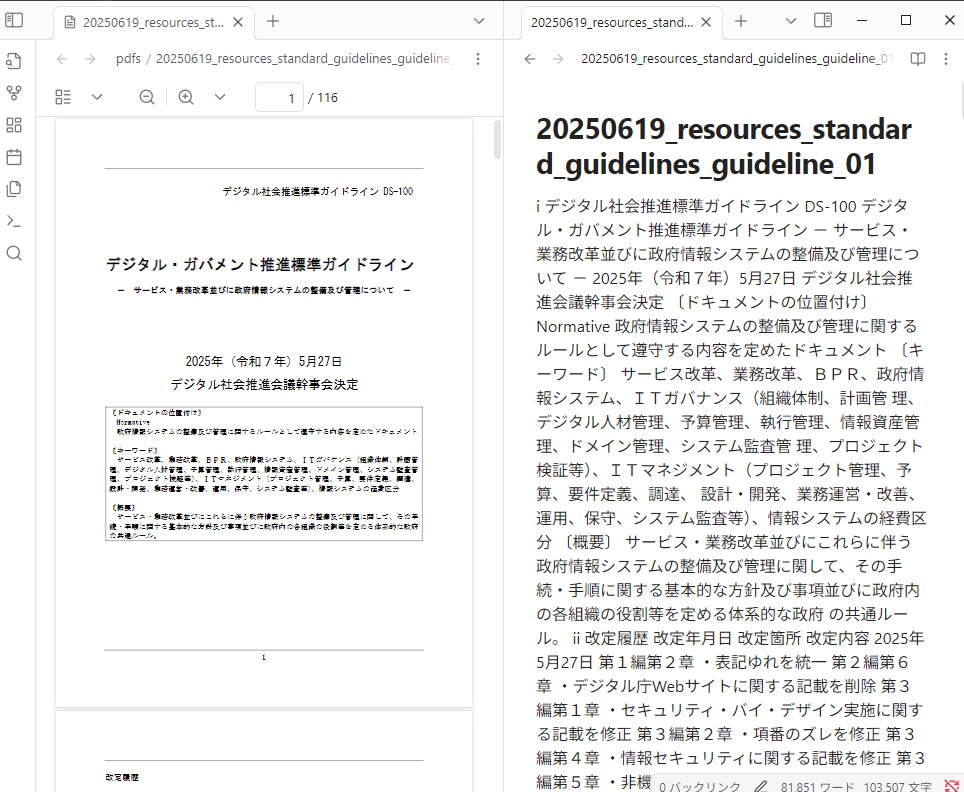
テストとして、デジタル庁が配布している「DS-100 デジタル・ガバメント推進標準ガイドライン」で試したところ、正常に検索をすることができました。
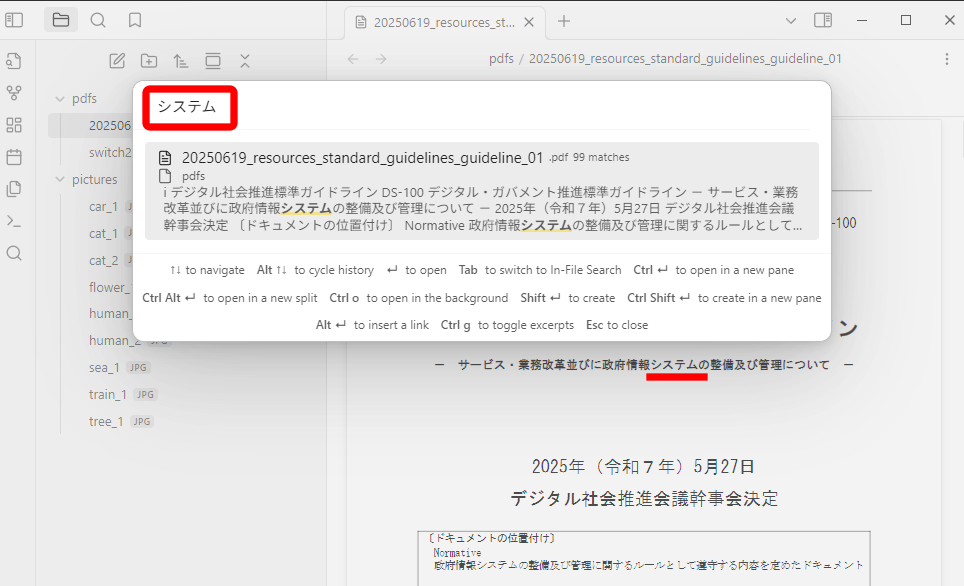
ところが、Nintendo Switch2の「安全に使用するために」では、何もヒットしません。
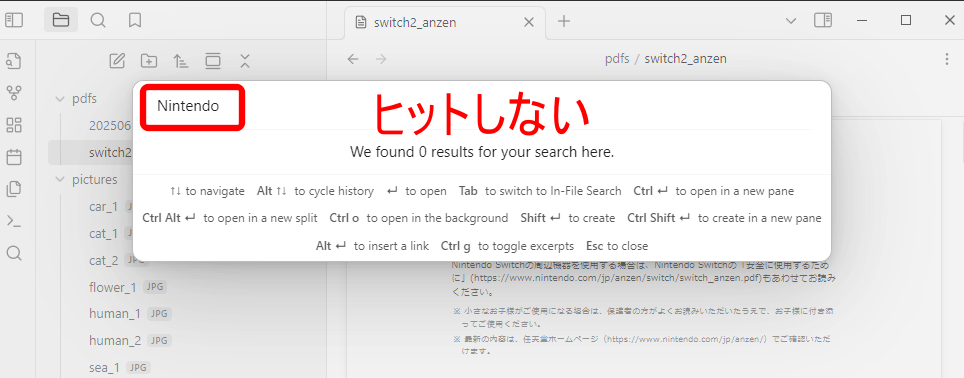
違いがあるかの確認のため、ファイルを右クリックし「Extract Text to clipboard」を選択します。
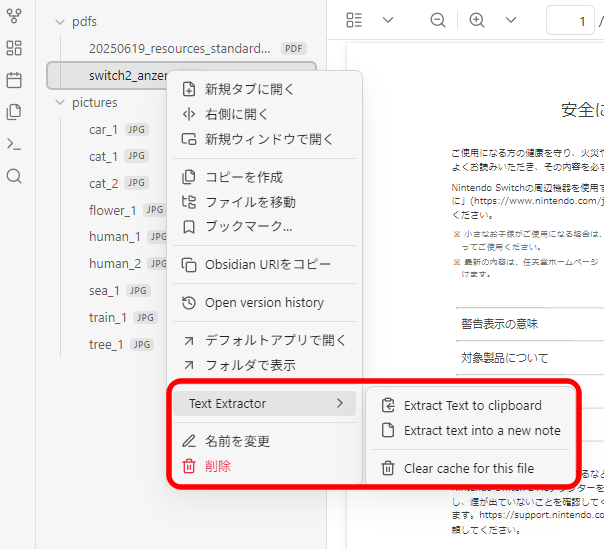
デジタル庁のPDFファイルからは正常にテキスト抽出されましたが、任天堂のPDFファイルは空となりました。
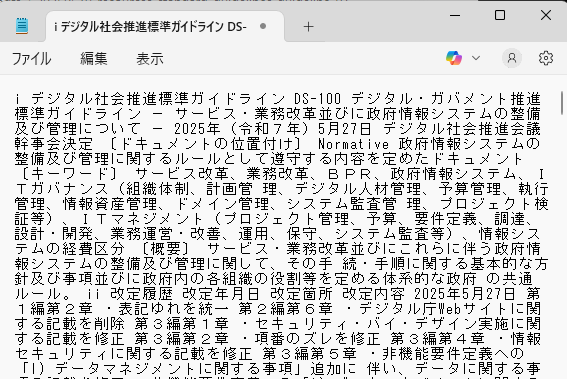
この問題はバグ報告されており、15%のPDFファイルで抽出に失敗するようです。
アップデートで改善されることを待つしかないと思われます。
OCR
こちらは、Wikipediaのページのスクリーンショット画像です。
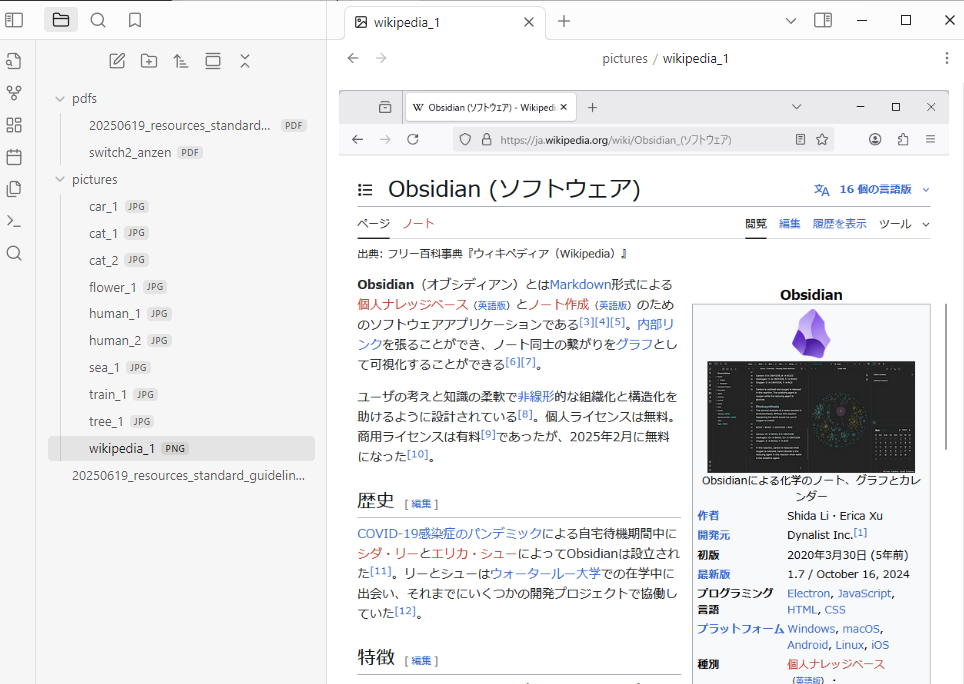
この画像に対してのOCR結果は、以下のようになっています。
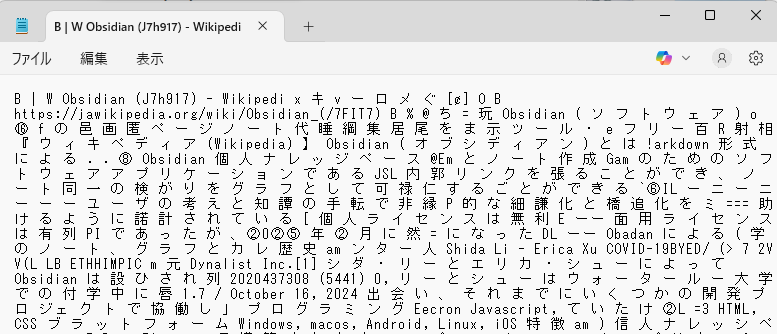
1文字ごとに分割されていて、文章として体を成していないので、検索に利用できることはほぼないと思います。
むしろ、検索の邪魔になりそうです。
Ollamaのインストール
「AI Image Analyzer」の前に、「Ollama」をインストールし、起動しておく必要があります。
モデルのダウンロードは、とりあえず不要です。
詳細は下記の記事をご参照ください。
-

中国のAI「DeepSeek-R1」をOllamaを使ってWindowsローカルで動かす方法
中国企業が開発した生成AIモデル「DeepSeek-R1」が話題となっており、アプリストアでもランキングを伸ばしていますが、プライバシー保護の観点から利用することは待ったほうが良いです。この記事では、 ...
AI Image Analyzerプラグインのインストール
Obsidianに「AI Image Analyzer」プラグインをインストールします。
「AI Image Analyzer」では、下記のモデルを使用することができます。
- llava-llama3(8B)
- llama3.2-vision(11B)
- llama3.2-vision(90B)
- llava(7B)
- llava(13B)
- llava(34B)
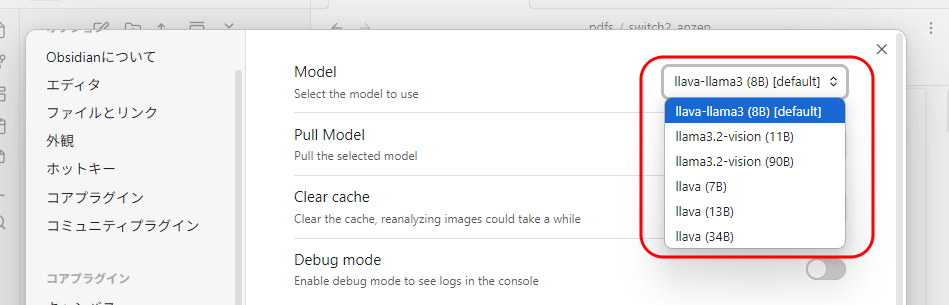
いくつか試しましたが、結局標準の「llava-llama3(8B)」が一番バランスが良いと感じました。
他のモデルは、処理に時間がかかったり、プロンプトが無視されたりしたので、色々と調整が必要になると思います。
使用するモデルを決めたら、「Pull Model」をクリックします。
自動的に、Ollamaでモデルがダウンロードされます。
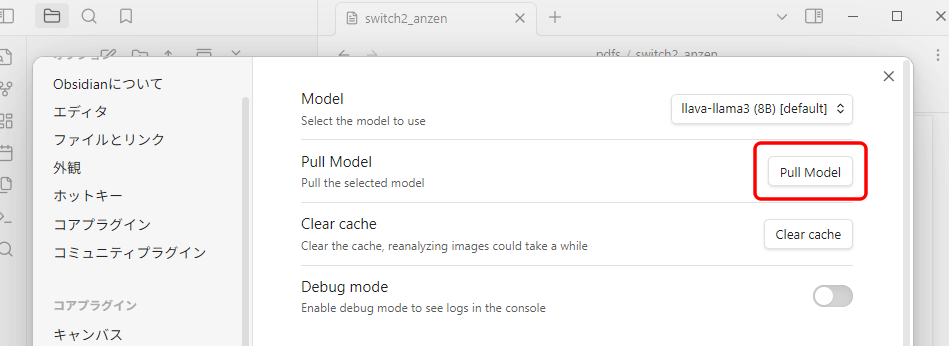
初期設定では、プロンプトが以下のようになっています。
Describe the image. Just use Keywords. For example: cat, dog, tree. This must be Computer readable. The provided pictures are used in an notebook. Please provide at least 5 Keywords. It will be used to search for the image later.
(画像を説明してください。キーワードのみを使用してください。例えば:「猫」「犬」「木」などです。これはコンピューターが読み取れる形式である必要があります。提供された画像はノートブックで使用されます。後で画像を検索するために、少なくとも5つのキーワードを提供してください。)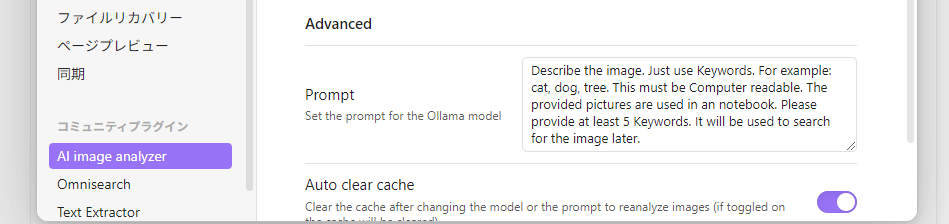
このままでは英語で出力されるので、日本語でも検索できるように、以下のプロンプトを追加します。
Describe the image. Just use Keywords. For example: cat, dog, tree. This must be Computer readable. The provided pictures are used in a notebook. Please provide at least 5 Keywords. It will be used to search for the image later. Also, include a Japanese translation of each keyword in parentheses.
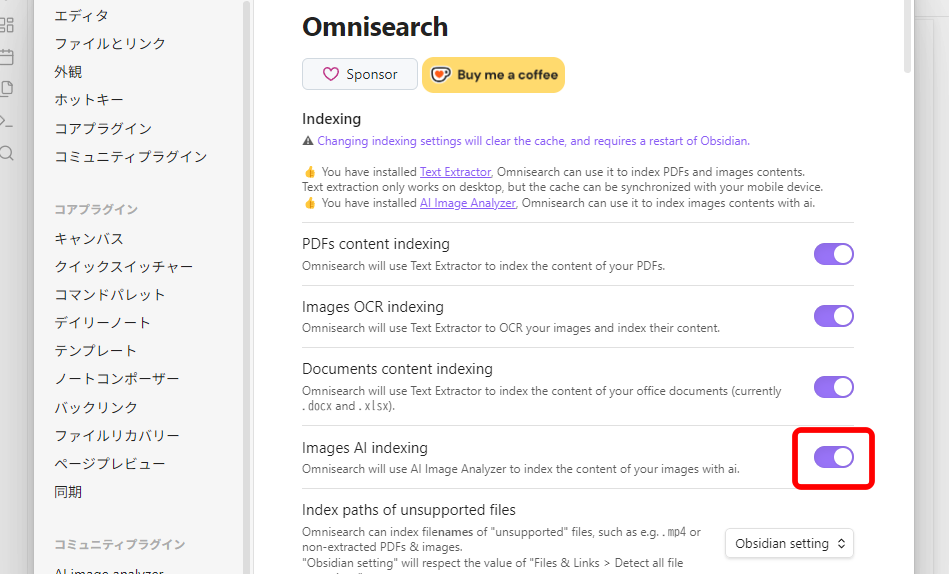
(画像を説明してください。キーワードのみを使用してください。例えば:「猫」「犬」「木」などです。これはコンピューターが読み取れる形式である必要があります。提供された画像はノートブックで使用されます。後で画像を検索するために、少なくとも5つのキーワードを提供してください。各キーワードには日本語訳を括弧内に含めてください。)「Omnisearch」の設定画面で、「Image AI Indexing」をオンにします。
その後、Obsidianの再起動が必要となります。
AI Image Analyzerプラグインの使い方
画像がどのように解析されたかは、ファイルを右クリックして「Analyze image to clipboard」から確認できます。
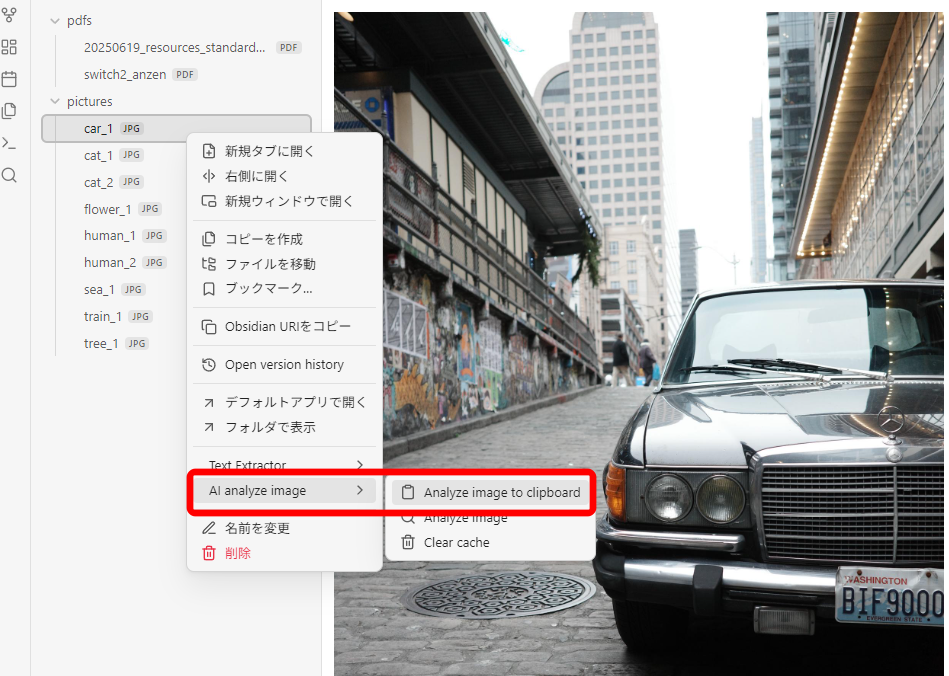
例えばこの車の画像は、最初の英語のプロンプトの場合は、以下のような結果となりました。
Car, silver car, city street, brick road, graffiti on building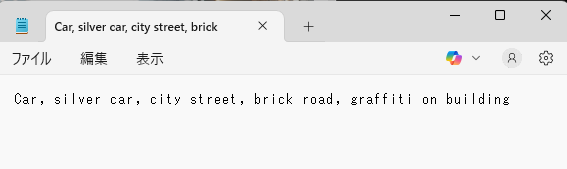
少し物足りなくはありますが、それなりに正しい結果と言えると思います。
次に、こちらの猫の画像で、日本語翻訳プロンプトを追加したバージョンで試してみます。
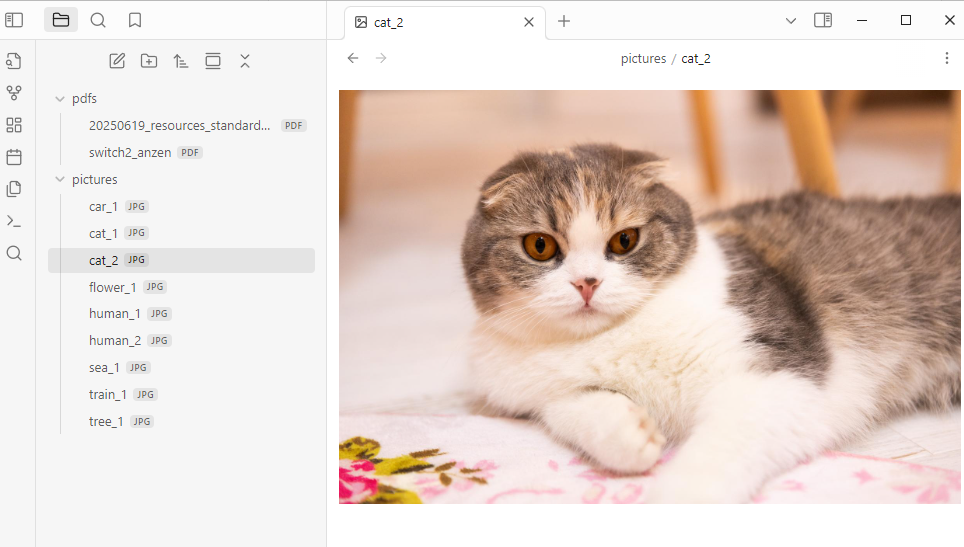
以下の結果となりました。
cat(ねこ), white(はいばさ), pink(ぴんくす), table(テーブル)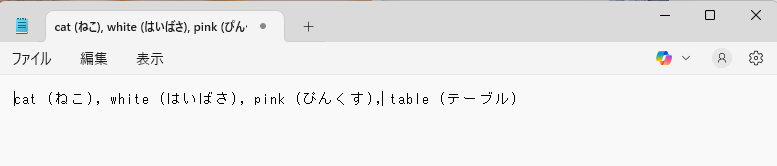
うーん……
画像解析の結果自体がいまいちではありますが、日本語翻訳が壊滅的です。(はいばさとは一体……)
また「ねこ」にしても、「猫」や「ネコ」ではヒットしないという、表記ブレが問題となります。
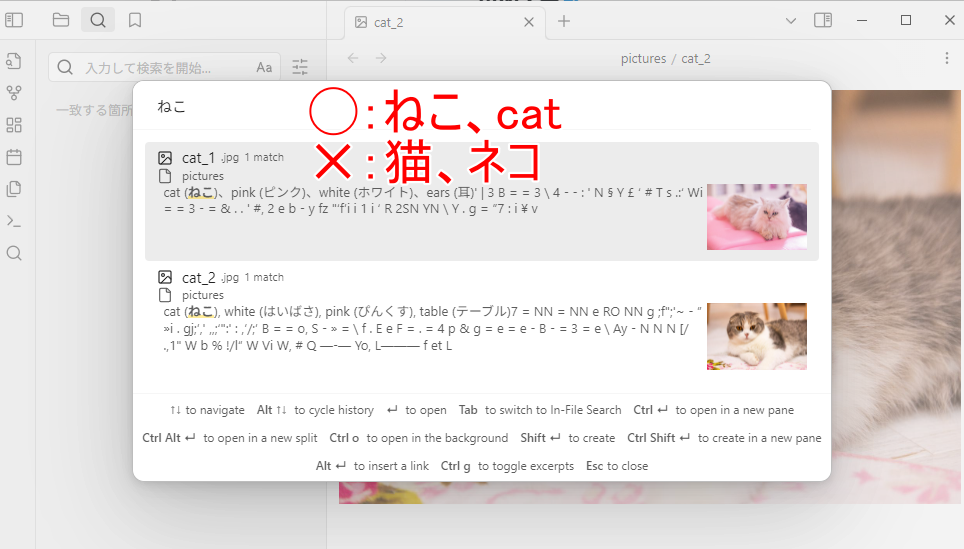
もう少し賢いAIモデルであれば、この辺りも正確に処理してくれるとは思いますが、「llava-llama3(8B)」では無理なようでした。
上位モデルでも試してみたのですが、プロンプトが完全に無視されて、箇条書きではなく、長文で回答されました。英語のみで使うのであれば、それでもいいかもしれません。
日本語翻訳は、無いよりはマシとは言えるかもしれませんが、中途半端にあるくらいであれば、逆に邪魔になるかもしれません。
まとめ ObsidianでPDF/画像検索できるようにするプラグインについて
Obsidianは、ノートファイルが数千を超えると、検索が遅くなるという問題があります。
Omnisearchプラグインは、検索インデックスを作成することで、この問題を解決します。
Text Extractorは、PDFからのテキスト抽出と、画像のOCR機能を提供するプラグインです。PDFは抽出に稀に失敗することがあります。OCRは、文章が1文字ごとに分割されるので、検索にはほぼ役に立ちません。
AI Image Analyzerは、画像解析をするプラグインですが、日本語翻訳に(ほぼ)対応しておらず、日本語で検索をすることができません。
Omnisearchは便利ですが、Text ExtractorとAI Image Analyzerの信頼性は低いです。
今後のアップデートに期待したいところです。

