
一般的に、好きな声で喋るTTS(Text-to-Speech)モデルを作成するには、学習用データを用意することが大変ですが、Style-Bert-VITS2とGPT-SoVITSを組み合わせれば、数秒の音声ファイルから作成することができます。さらにAivisSpeechのモデルに変換し、SillyTavernと連携すれば、好きな声で喋るAI彼氏、AI彼女を作ることも可能です。この記事では、その手順を、分かりやすく解説しています。
GPT-SoVITSで音声データを生成し、Style-Bert-VITS2で学習する方法
数秒の音声ファイルと、ChatGPTで作成した台本を使い、GPT-SoVITSで音声ファイルを大量作成し、Style-Bert-VITS2に学習させる方法を解説します。
Style-Bert-VITS2とは
「Style-Bert-VITS2」とは、感情やスタイルを制御する機能を備えた、音声合成(TTS)モデルです。
名前がややこしいのですが、以下の技術を組み合わせたことを意味しています。
- VITS(Variational Inference Text-to-Speech): 自然な音声とリアルタイム性を両立したTTSモデル
- VITS2: VITSの進化系で、より高品質な音声を生成
- BERT(Bidirectional Encoder Representations from Transformers): Googleが開発した、テキストの文脈を理解するモデル
- Style-Bert: BERTを使って、テキストから感情を推定し、話し方の「スタイル」を決める手法
これにより、Style-Bert-VITS2は、テキストから感情豊かな音声を生成することができるモデルとなっています。
オープンソースで開発されており、無料で使用することができます。
ただしモデルを公開する際は、非商用であったとしても、著作権、肖像権、パブリシティ権など多くの法的問題がありますので、十分にご注意ください。
今回の目的と作業の流れ
今回の目的は、「自分の好きな声で喋る音声合成モデルを作成し、AIロールプレイングシステムSillyTavernと連携する」ことです。
そのために、以下のような手順を踏みます。
- 数秒の音声サンプルを用意する
- GPT-SoVITSで大量に増幅させる
- Style-Bert-VITS2に学習させ、TTSモデルを作成する
- 使いやすいように、AivisSpeechのモデルに変換する
- SillyTavernと連携する
すべてWindowsのローカル環境で、無料にて、実行できます。
NVIDIAのGPUは必要となります。
長くなりますし、多少面倒ではありますが、そこまで難しくはありませんので、お付き合いいただけますと幸いです。
学習用音声データを作成する
数秒のサンプル音声から、GPT-SoVITSを使って大量の音声ファイルを作成する方法をご紹介します。
サンプル音声の用意
まず元となる音声データとして、3~10秒のwavファイルが必要となります。
ノイズがのっておらず、高音質なものが望ましいです。
ここでは、既に用意されているものとします。
ノイズ除去については、こちらの記事をご参照ください。
-


音声ファイルからBGMやノイズを除去するAudacityとOpenVINOプラグインの使い方
TTSで音声学習をしようとする際、高品質な音声データが必要となりますが、BGMやノイズが入っていたりして、なかなか適切な素材を用意することは大変です。Audacityを使用すれば、完璧ではありませんが ...
台本の用意
この音声ファイルをもとに、GPT-SoVITS(これもTTSモデル)を使って、別の音声ファイルを作成してきます。
そこで、何を喋るのかというテキストが必要となるのですが、ChatGPTに作成してもらいました。
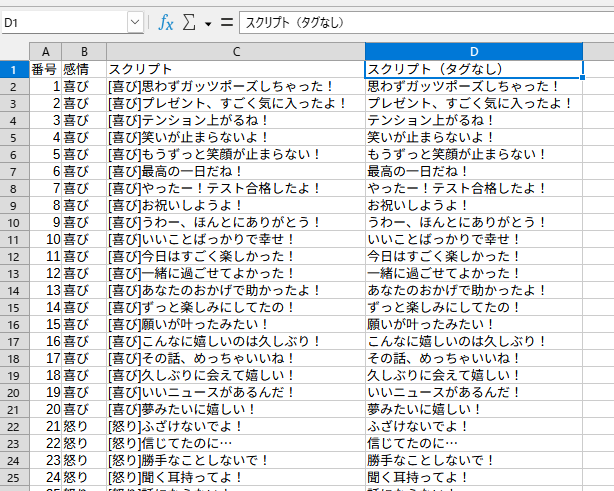
学習用データとして、どの程度の量が必要なのかは、やってみないと分からないということなので、とりあえず例文100個用意しました。
サンプルとして、CSVファイルを置いておきます。
雑に作成しただけであり、特に最適化されている訳でもないので、参考程度としてください。
また、今回実際に使用しているのはD列のみです。
感情タグは、何かの時に使えるかもしれないということで、残してあります。
GPT-SoVITSで音声データを生成
サンプル音声と台本を使って、GPT-SoVITSで音声ファイルを生成していきます。
詳細は、下記の記事をご参照ください。
-

5秒の音声データからAI音声を生成できるGPT-SoVITSの使い方
2025/5/30 AivisSpeech, AI彼女, AI彼氏, TTS
GPT-SoVITSは、数秒程度の音声サンプルから、似た声の音声を生成できるTTSです。これにより、自分の声や、好きな声を使って、AIボイスを簡単に生成することができます。この記事では、Windows ...
audio_001.wavからaudio_100.wavまで、100個のファイルが作成されることになります。
今回は、音声を確認しながら手動で行いましたが、もっと数を増やすのであれば、APIを使った一括処理の検討をしてもいいかもしれません。
ファイルリストの作成
作成した音声ファイルと、文字起こししたテキストを対応付けた「esd.list」というテキストファイルを作成します。
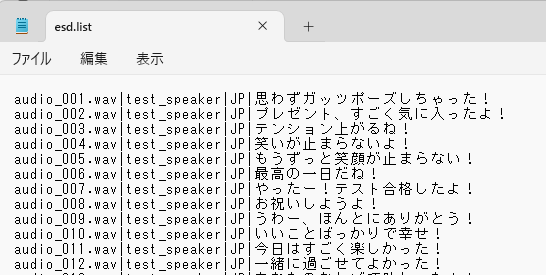
フォーマットは、以下のようになっています。
音声ファイル名|モデル名|言語|テキストサンプルとしてファイルを置いておきます。ファイル名を「esd.list」に変更してください。
このファイルは、後ほど使用します。
Style-Bert-VITS2で音声学習する
生成した音声ファイルを使用し、Style-Bert-VITS2で学習し、オリジナルのTTSモデルを作成します。
Style-Bert-VITS2のインストール
Windowsに「Style-Bert-VITS2」をインストールします。
GitHubのページを開き、「このzipファイル」からファイルをダウンロードします。

任意のフォルダに展開します。
「sbv2」というフォルダが作成されると思います。
その中にある「Install-Style-Bert-VITS2.bat」をダブルクリックして実行します。
コマンドプロンプトが開き、インストールが開始されます。
おそらく数十分かかると思います。
途中でファイアウォールの警告が表示された場合は、「許可」してください。
ブラウザで「http://localhost:8000/」が開き、以下のような画面となれば完了です。
利用規約を読み、「同意する」をクリックします。
音声合成のテスト
Style-Bert-VITS2は、デフォルトのモデルを内蔵しているので、このまま音声合成をすることもできます。
「テキスト」を入力し、「音声合成」をクリックします。
正常に生成されることが確認できたら、この画面はもう使用しないので、ブラウザのタブとコマンドプロンプトは閉じておきます。
WebUIの起動
「sbv2\Style-Bert-VITS2」フォルダの「App.bat」をダブルクリックして実行します。
ブラウザで「http://127.0.0.1:7860/」が開き、以下のような画面となります。

データセットの準備
次に、学習用音声データファイルを準備します。
この作業は「データセット作成」タブで行うこともできるのですが、今回は前作業で済んでいるので、手動でファイルを配置していきます。
「sbv2\Style-Bert-VITS2\Data」フォルダに、「モデル名」(ここではtest_speaker)フォルダを作成します。
そのフォルダの中に、「raw」フォルダを作成します。
また上記で用意した「esd.list」ファイルを置きます。
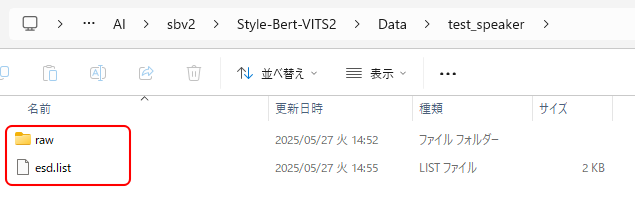
「raw」フォルダの中に、音声ファイルを置きます。
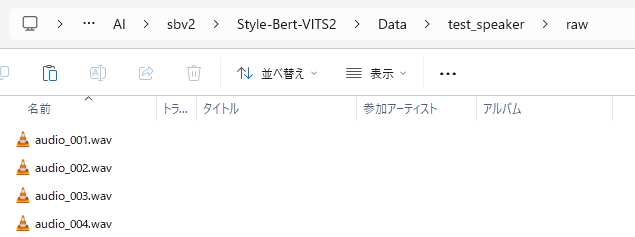
以上で、準備は完了です。
学習の開始
ブラウザの画面に戻り、「学習」タブを選択します。
「モデル名」を正確に入力し、「自動前処理を実行」をクリックします。
完了まで、そこまで時間はかからないと思います。
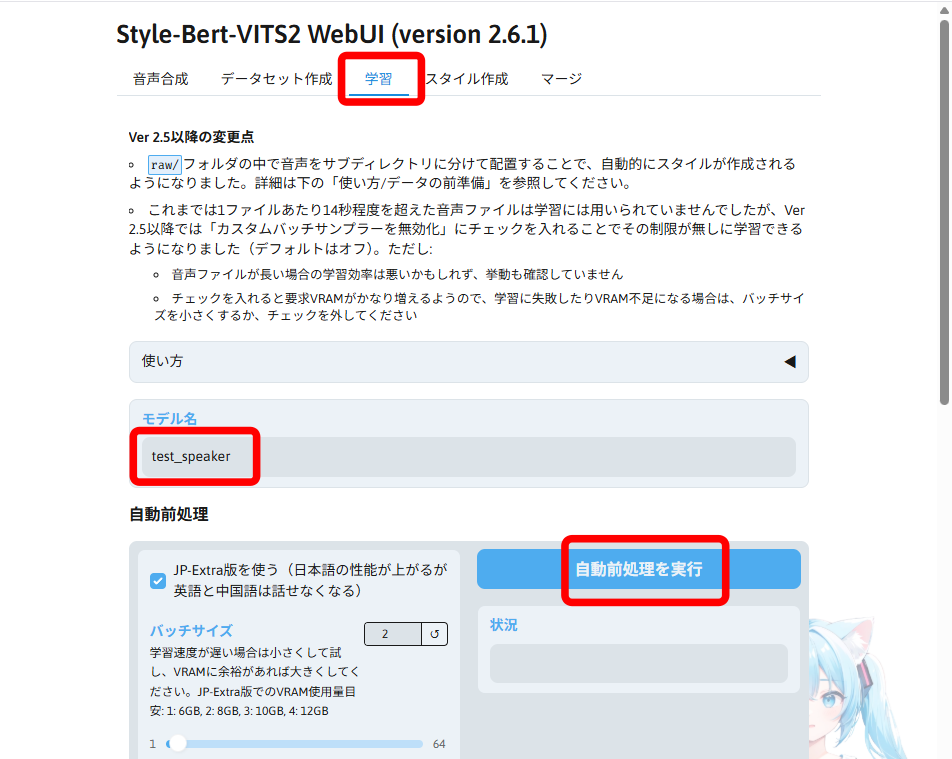
「学習を開始する」をクリックします。
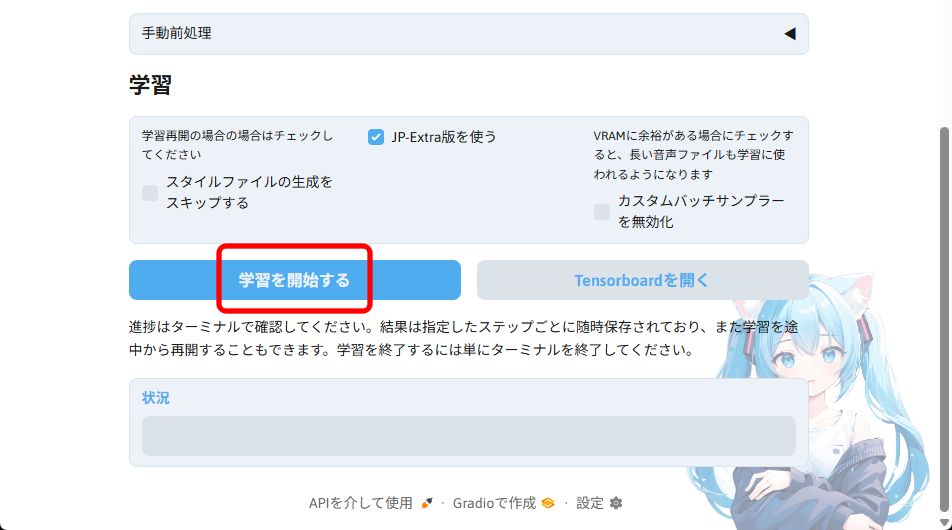
コマンドプロンプトで進行状況を確認できます。
私の環境では、100ファイルで、ちょうど1時間ほどかかりました。
完了すると、「sbv2\Style-Bert-VITS2\model_assets」フォルダに、モデル名のフォルダが作成されています。
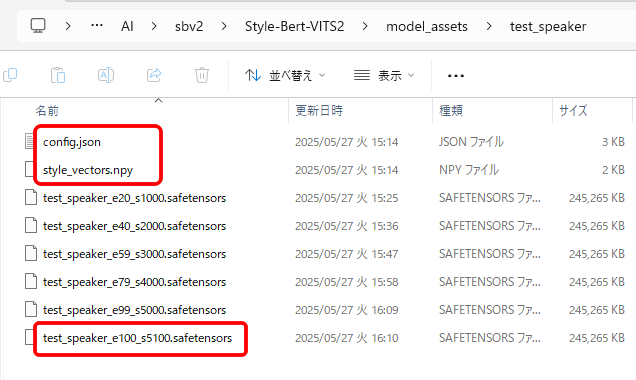
フォルダの中はこのような感じです。
必要なのは「config.json」、「style_vectors.npy」、最後に作成された「.safetensors」の3つです。
その他は、処理を中断した時に再開できるように、一時保存されたものです。
作成したモデルのテスト
作成したモデルを使って、さっそく音声合成をテストしてみましょう。
「音声合成」タブを選択します。
「更新」をしてから、モデルを「ロード」します。
「テキスト」を入力し、「音声合成」をクリックします。
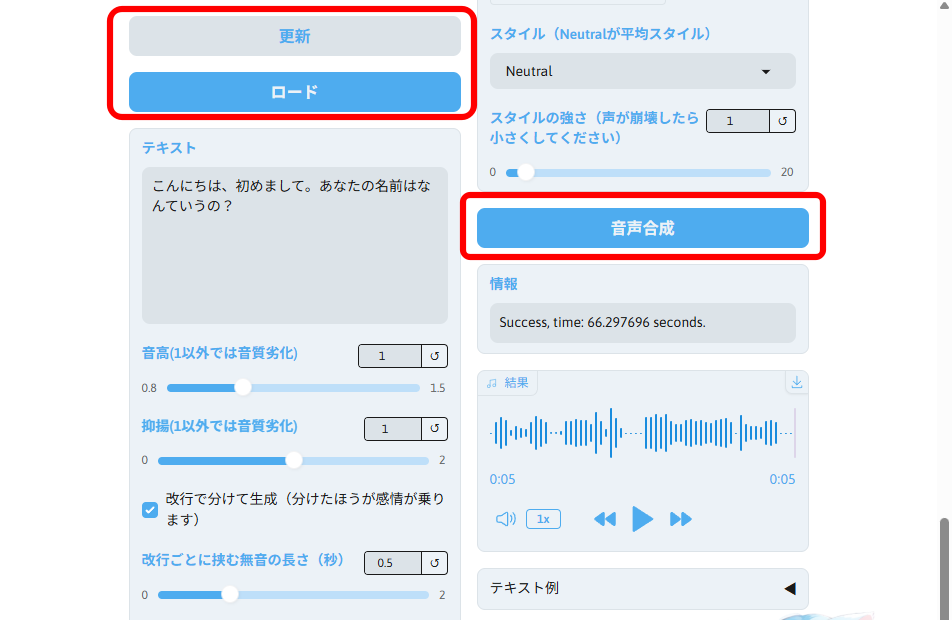
出来上がった声が、元の声と似ているかと言われれば、30点くらいでしょうか。
声質は似ていると思います。
しかし声が似ているというのは、話す速度、抑揚、言葉の選び方などが総合的に関係してくるので、それはまた別問題となります。
5秒のサンプル音声から、ここまで似せることができるのであれば、かなりいいのではないかと思います。
Style-Bert-VITS2のモデルをAivisSpeech用に変換する方法
Style-Bert-VITS2で作成したオリジナルTTSモデルを、AivisSpeechで利用できるように変換する方法をご紹介します。
AivisSpeechのインストール
Style-Bert-VITS2のモデルは、そのままでも使えますが、AivisSpeechで使える形に変換することで、モデルの切り替えや配布が簡単になります。
AivisSpeechのインストールと使い方は、下記の記事をご参照ください。
-

AivisSpeechとSillyTavernを使って、CotomoのようなおしゃべりAIを完全ローカルで実行する方法
2025/10/9 AivisSpeech, AIロールプレイ, AI彼女, AI彼氏, LM Studio, SillyTavern, TTS
オリジナルキャラクターや、AI彼氏・AI彼女と音声チャットを楽しみたい、でもCotomoのようなクラウドサービスはプライバシーが心配、という方向けに、全てWindowsローカル環境で動作するシステムを ...
ONNXファイルの準備
AivisSpeechのモデルを作成するには、「Safetensors」と「ONNX」の2つのファイルが必要となります。
Safetensorsファイルは既にありますが、ONNXファイルがありません。
これを用意する必要があります。
Aivis Projectの変換ツールがまだ使えない
AivisSpeechでは、SafetensorsからONNXに変換するツールも用意しています。
「Aivis Project」のサイトにアクセスし、「AI音声合成をつくる」をクリックします。
「AIVMファイルを作る」をクリックっします。
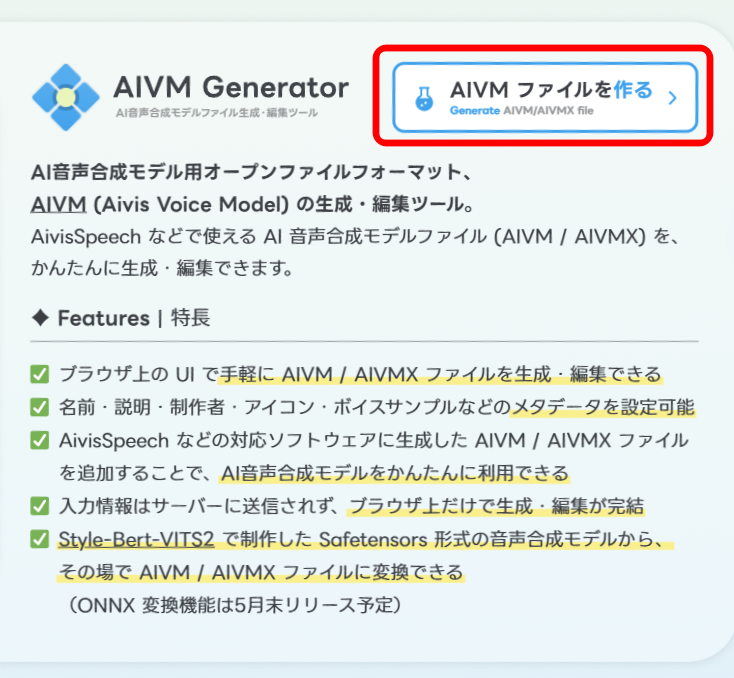
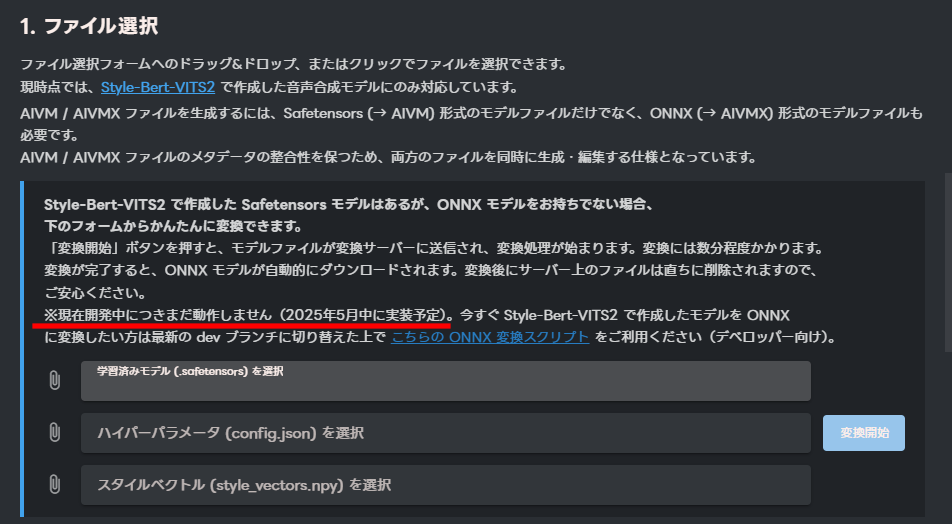
ONNXモデルへの変換ツールは、現在開発中とあります。
2025年5月中に実装予定とのことですが、5月27日現在、まだ使用できませんでした。
Style-Bert-VITS2の開発バージョンを取得する
そこで、Style-Bert-VITS2の機能を使って、手動でONNXモデルに変換していきます。
開発版を取得する必要があるため、少し手間ではあります。
コマンドプロンプトを開き、「sbv2\Style-Bert-VITS2」フォルダに移動します。
次のコマンドを順番に実行します。
git checkout dev
git pull origin dev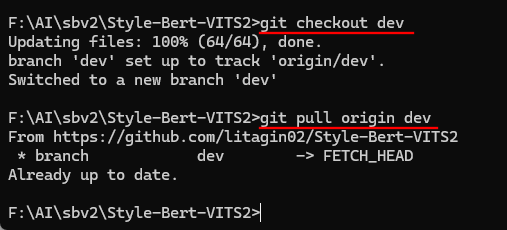
一つ上のフォルダの「Update-Style-Bert-VITS2.bat」を実行します。
完了まで、少し時間がかかるかもしれません。
変換スクリプトの実行
元のフォルダに戻り、以下のコマンドを実行し、仮想環境を有効にします。
.\venv\Script\activate
仮想環境で次のコマンドを実行し、SafetensorsからONNXに変換をします。
「convert_onnx.py」と「convert_bert_onnx.py」があるので、ご注意ください。
「convert_onnx.py」の方です。
python convert_onnx.py --model .\model_assets\【モデル名】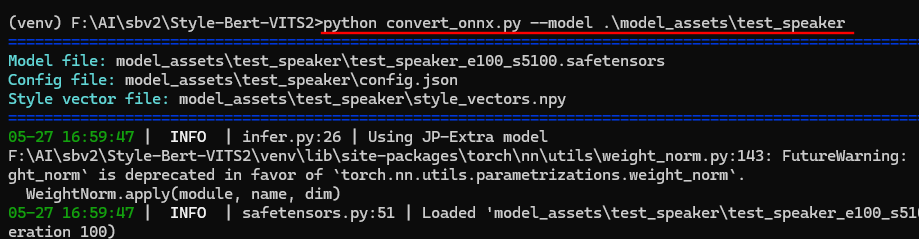
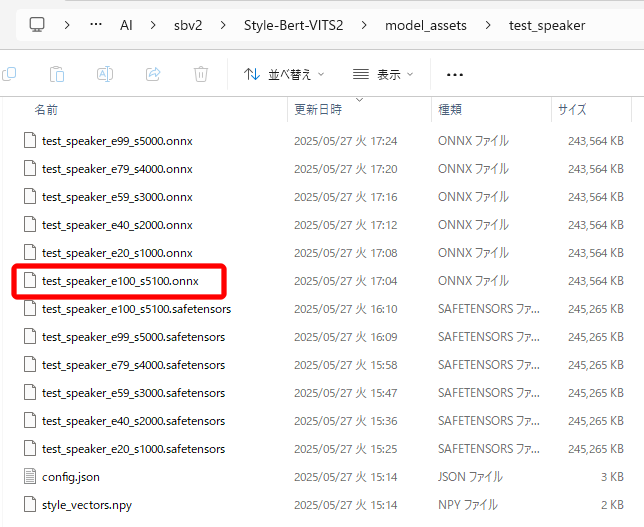
変換が完了すると、以下のように「.onnx」ファイルが作成されます。
(必要なファイルは最新のものだけなので、事前に削除しておけばよかったかもしれません)
AIVMファイルの作成
「config.json」「style_vectors.npy」「.safetensors」「.onnx」ファイルを使い、AivisSpeech用のモデルを作成します。
AIVM Generatorの実行
AIVM Generatorのページに戻り、作成したファイルをアップロードします。
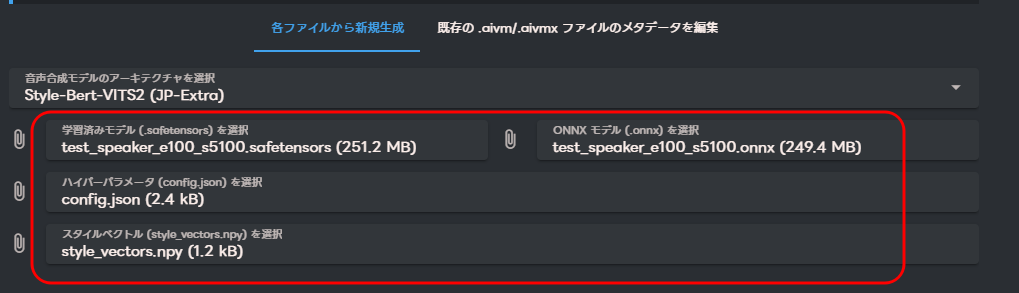
メタデータは自動的に入力されます。
必要であれば、モデルの説明を追記してください。
今回はモデルの公開・配布を行いませんが、公開する場合はライセンスをよく確認する必要があります。
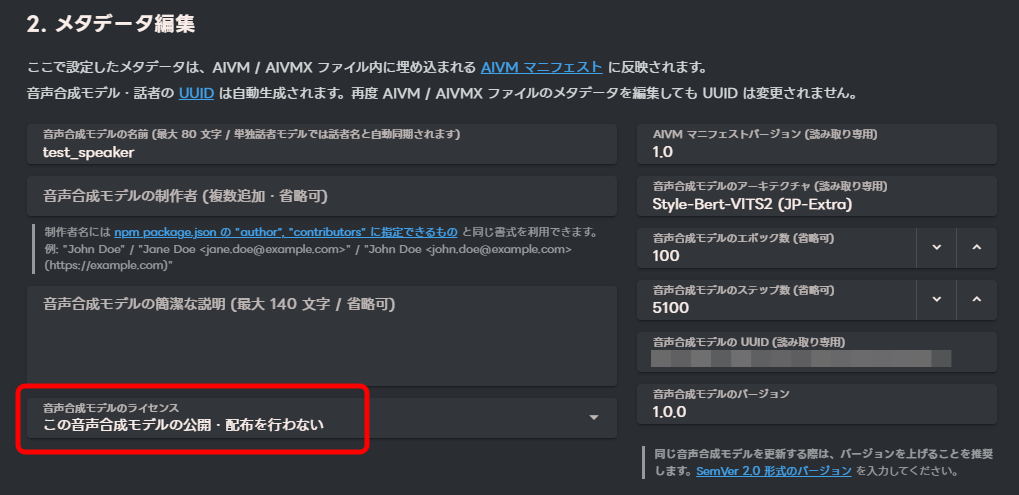
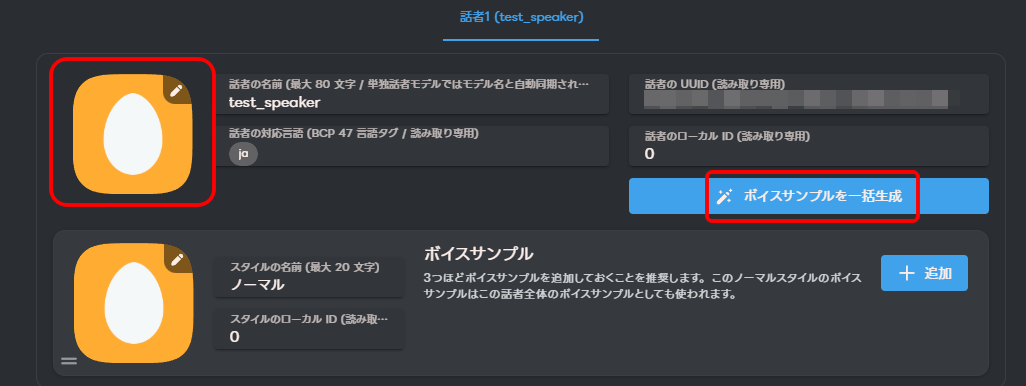
必要であれば、アイコンの変更や、ボイスサンプルの登録を行います。
「上記メタデータでAIVM/AIVMXファイル(.aivm/.aivmx)を生成」をクリックします。
すぐに完了し、ファイルがダウンロードされます。

AIVMモデルの読み込み
AivisSpeechを起動し、実際に音声合成をしてみましょう。
「設定」から「音声合成モデルの管理」をクリックします。
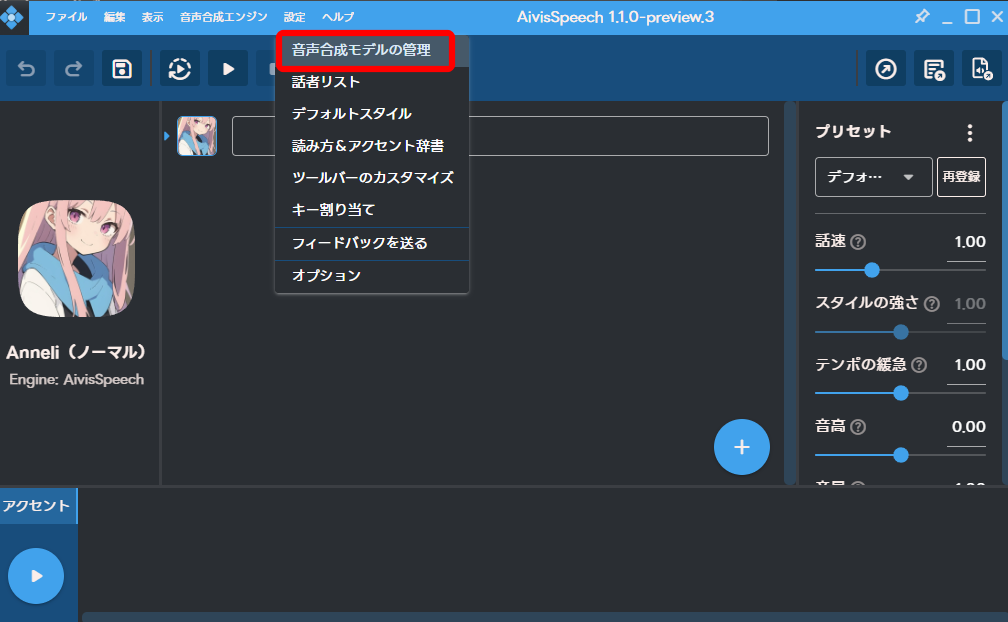
右上の「インストール/更新」をクリックします。
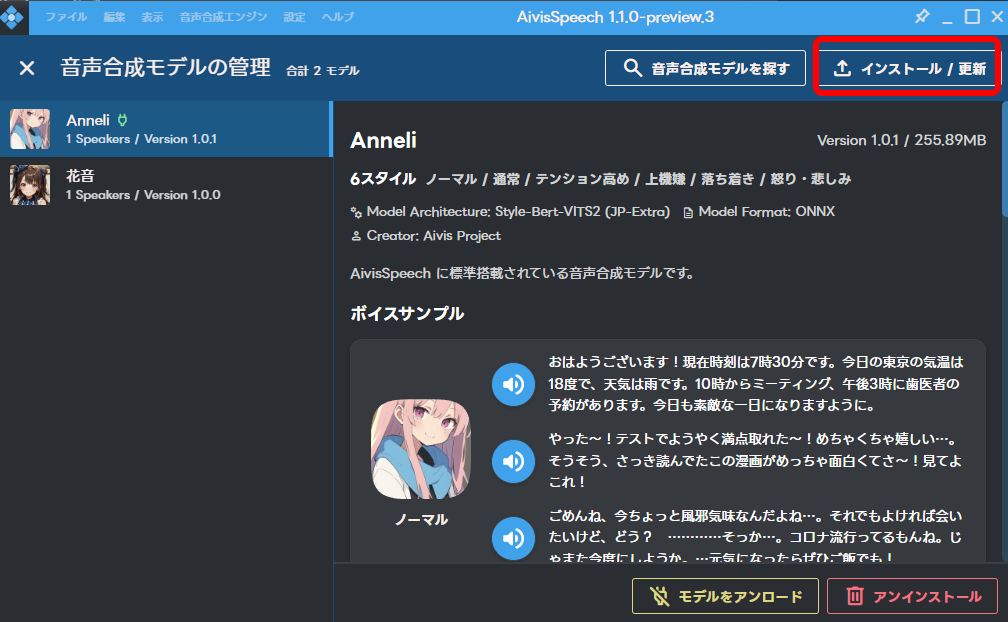
ダウンロードした「.aivmx」ファイルを選択し、右下の「インストール/更新」をクリックします。
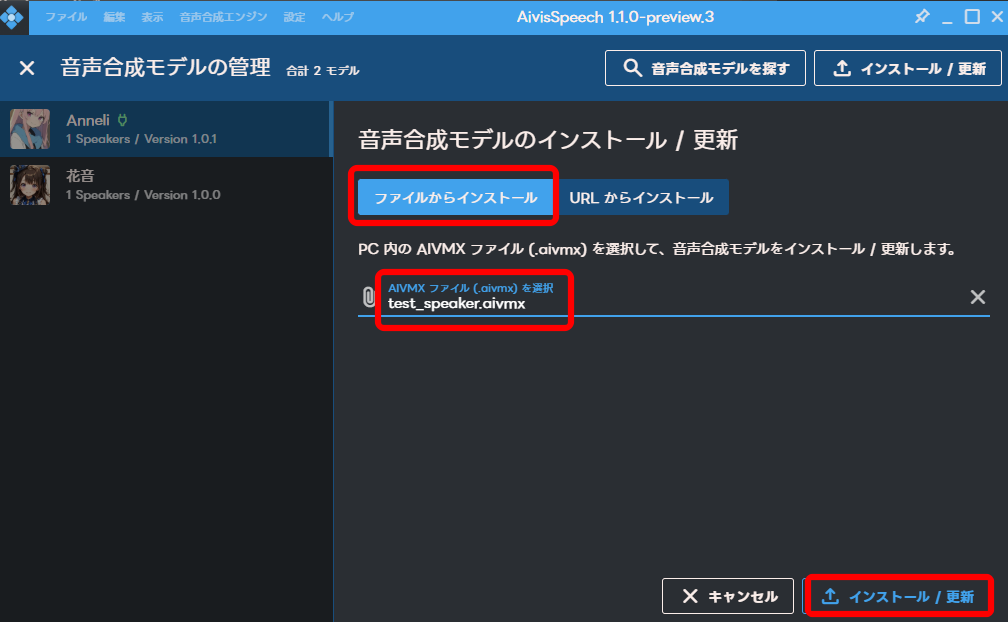
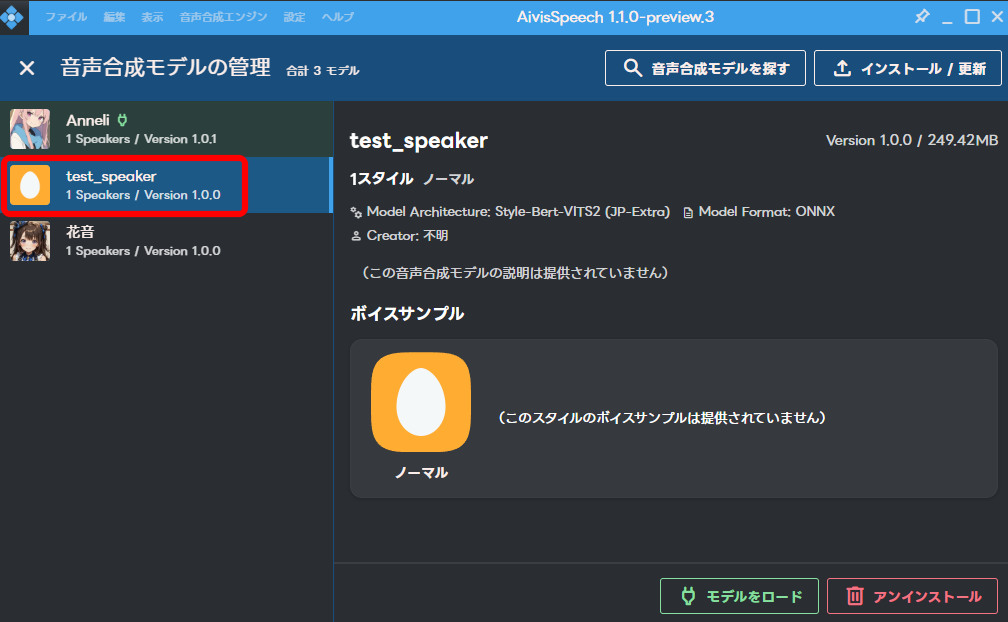
モデルが読み込まれました。
この画面でさみしいので、アイコンの変更や、ボイスサンプルの登録は行っておいた方がいいと思います。
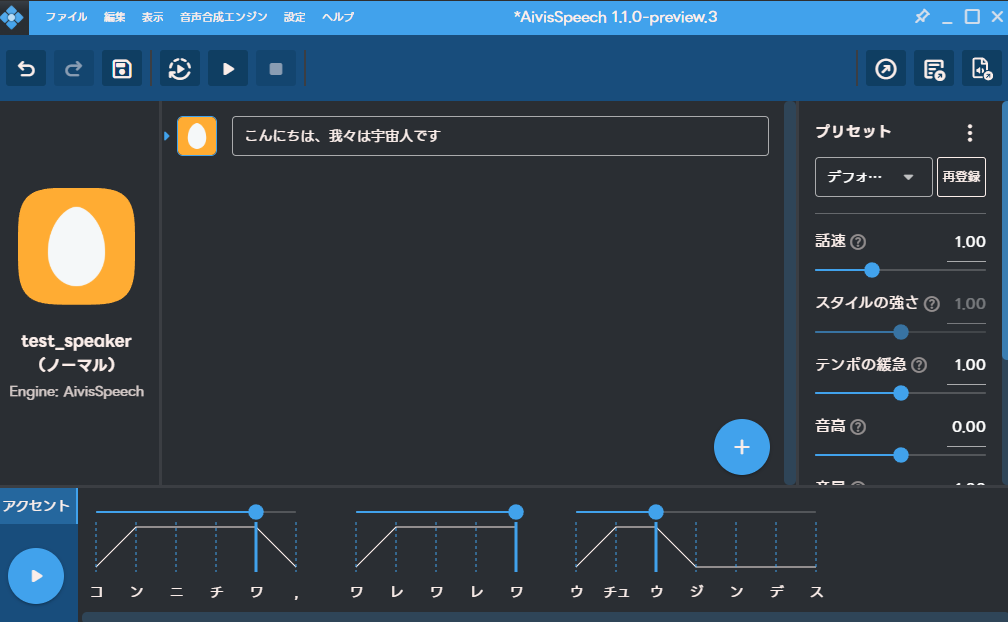
もちろん、テキストから音声合成をしたり、アクセントを変更したりすることができます。
SillyTavernとの連携
ここまでくれば、SillyTavernと連携し、自分で作成したキャラクターに、自分の好きな声で喋らせることができるようになります。
-
AivisSpeechとSillyTavernを使って、CotomoのようなおしゃべりAIを完全ローカルで実行する方法
2025/10/9 AivisSpeech, AIロールプレイ, AI彼女, AI彼氏, LM Studio, SillyTavern, TTS
オリジナルキャラクターや、AI彼氏・AI彼女と音声チャットを楽しみたい、でもCotomoのようなクラウドサービスはプライバシーが心配、という方向けに、全てWindowsローカル環境で動作するシステムを ...
AivisBuilderを待とう
こんな面倒な作業はやっていられない!
という方も多いと思います。
上記の作業を全てまとめて実行できる、AivisBuilderを開発中とのことなので、それを待ちましょう。
2025年の夏頃に公開予定です。
まとめ Style-Bert-VITS2の使い方とは
Style-Bert-VITS2は、感情豊かな音声を生成できるTTSモデルです。
Style-Bert-VITS2に、好きな声で喋らせるように学習させるには、大量の音声データが必要となります。
GPT-SoVITSを利用すれば、数秒の音声データから、音声データを大量生成できます。
これにより、好きな声で喋るオリジナルのTTSモデルを、簡単に作成することができます。
さらに、AivisSpeech用のモデルに変換すれば、モデルの管理が容易になります。
SillyTavernと連携すれば、好きな声で喋る、AI彼氏・AI彼女を作ることも可能です。
外部に公開する際は、権利関係をよく確認するようにしましょう。

