
画像生成AIに興味があるけど、何から初めていいのか分からないという方には、Easy Diffusionをおすすめします。Easy Diffusionを使えば、インストーラーで数回クリックするだけで、ローカルにStable Diffusionの環境を簡単に構築できます。この記事では、Easy Diffusionのインストールと、最低限必要な画像生成の知識について、分かりやすく解説しています。
Stable Diffusionをローカル環境で実行するメリット
Stable Diffusionの概要と、ローカルで実行するメリット・デメリットについて解説します。
Stable Diffusionとは
「Stable Diffusion(ステイブル・ディフュージョン)」とは、画像生成AIのフレームワークです。
テキストから画像を生成する「text-to-image」を得意としています。
既存の画像の一部を変更したり(inpainting)、画像から画像を生成(image-to-image)することもできます。
Stable Diffusionは、2022年にStablility AI社によって、オープンソースにて公開されました。
Stable Diffusionは、様々なクラウドサービスに組み込まれていますが、ローカル環境で実行することもできます。
下記では、ローカルで実行するメリット・デメリットについてご紹介します。
ローカルで実行するメリット
Stable Diffusionをクラウドではなく、ローカルのPCで動かすメリットをご紹介します。
無料
Stable Diffusionが使えるクラウドサービスの多くは、基本無料で、機能や回数によって追加料金が必要となることが多いです。
ローカル環境を構築すれば、全て無料で利用できます。
(PCや電気代は必要ですが)
プライバシーの保護
多くのクラウドサービスではデータが検閲されていたり、別の用途に利用されたりしています。
ローカル環境で実行すれば、使用したプロンプト(テキスト)や成果物が外部に送信されることはなく、誰にも見られることはないので安心です。
機能制限なし
多くのクラウドサービスでは、機能が制限されていたり、特定のプロンプトがブロックされていたりします。
ローカルであれば、何にも縛られることはなく、自由に創造性を発揮できます。
ただし、成果物を外部に公開したり、商用利用したりしようとすると話が変わってきますので、その点はご注意ください。
回数制限なし
現状AIによる画像生成は、一発で思い通りにいくということはなく、何度もプロンプトを調整したり、同じプロンプトで複数の画像を生成したりして、たまたま上手く行ったものを引き当てるという感じの作業となります。
ローカルであれば回数を気にする必要はなく、何度でも気が済むまで繰り返すことができます。
カスタマイズ可能
ローカルであれば、自分の目的に合うように機能をカスタマイズしたり、最新のツールをいち早く導入したりということが可能となります。
ローカルで実行するデメリット
ローカルでStable Diffusionを実行するデメリットをご紹介します。
遅い
一般的にローカルで画像生成をしようとすると、クラウドよりも時間がかかります。
内容によっては一回の画像生成に数分から数十分かかることもあるでしょう。
それがストレスになる場合は、クラウドサービスに課金をした方がいいかもしれません。
ハイスペックPCが必要
画像生成AIを実行するためには、高性能なGPUを搭載した高価なPCが必要となります。
また実行中はPCのリソースを大量に使用するので、他の作業ができなくなりますし、電気代もかかります。
難しい
Stable Diffusionの環境を構築するためには、PythonやGitの知識が必要となり、エンジニアではない一般ユーザーにはややハードルが高いです。
この記事では、それをなるべく簡単にするEasy Diffusionというツールをご紹介しています。
Easy Diffusionで簡単にStable Diffusionのローカル環境を作る方法
Easy Diffusionを使ったStable Diffusionのインストール方法と、基本的な使い方について解説します。
Easy Diffusionとは
Easy Diffusionとは、Windows、macOS、Linux上にStable Diffusionの環境を簡単に構築できるツールです。
オープンソースで開発されており、無料で使用できます。
一般的にローカルのStable Diffusionの環境には、WebUI(Automatic1111)が広く使われていますが、初心者には難易度が高いです。
Easy Diffusionを使えば、誰でも簡単にAI画像生成を始めることができます。
(追記:Automatic1111も簡単な方法がありました)
-


ダブルクリックするだけ!Stable Diffusion WebUIをWindowsにインストールする方法
2025/3/7 Stable Diffusion, 画像生成
画像生成AIのStable Diffusionを実行する環境を構築するためには、専門知識が必要となると思われるかもしれませんが、実際にはファイルをダブルクリックするだけで完了します。この記事では、Py ...
WebUIとEasy Diffusionの違い
WebUIの方が設定が難しいですが、高度なことができます。
また広く使用されているので、情報も多くあります。
最初はEasy Diffusionでいろいろ試してみて、満足できなくなったら、WebUIに移行することをおすすめします。
必要スペック
WindowsでEasy Diffusionを使用するためには、以下のスペックが必要です。
- NVIDIAグラフィックカード(VRAM 4GB以上)
- 8GB以上のRAM
- 20GB以上の空き容量
グラフィックカードがない場合でも、代わりにCPUを使用するオプションがありますが、あまり現実的ではないようです。
Easy Diffusionのインストール
Windows PCにEasy Diffusionをインストールする方法をご紹介します。
ダウンロード
ブラウザで「https://easydiffusion.github.io/」を開き、「Download」をクリックします。
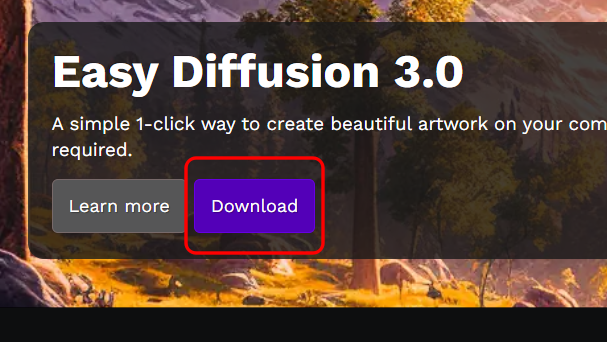
「Download for Windows」をクリックします。
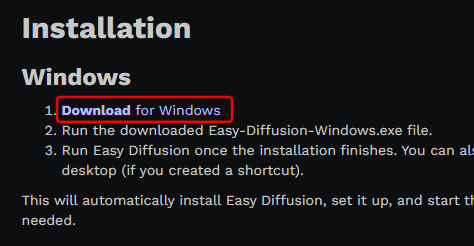
インストール
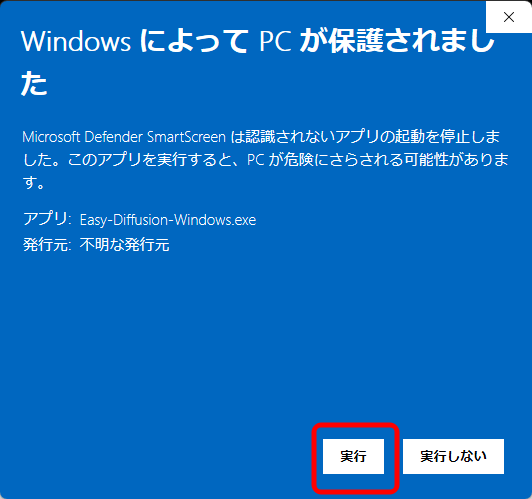
ダウンロードした「Easy-Diffusion-Windows.exe」をダブルクリックして実行します。
おそらく警告が表示されるので、「詳細情報」をクリックします。
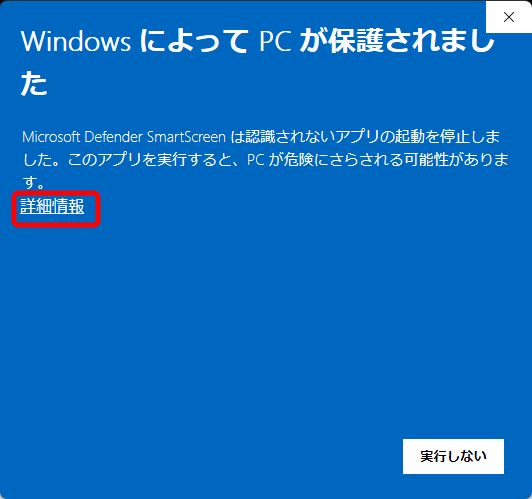
「実行」をクリックします。
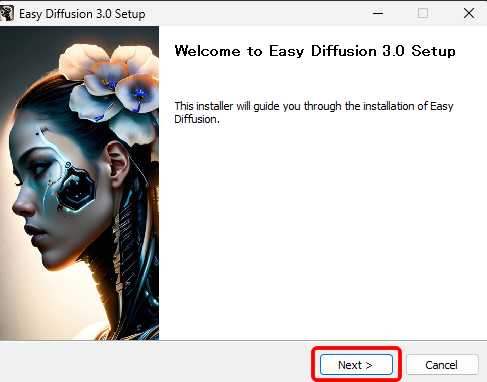
「Next」をクリックします。
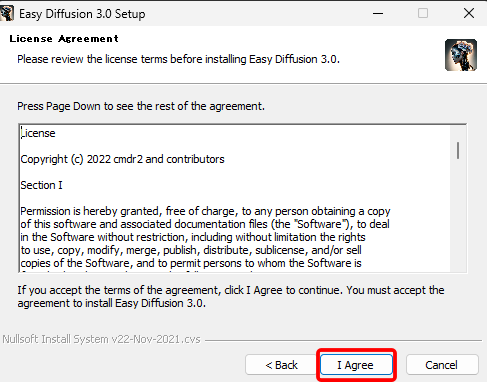
規約を確認し、「I Agree」をクリックします。
別の規約の内容も確認し、「I Agree」をクリックします。
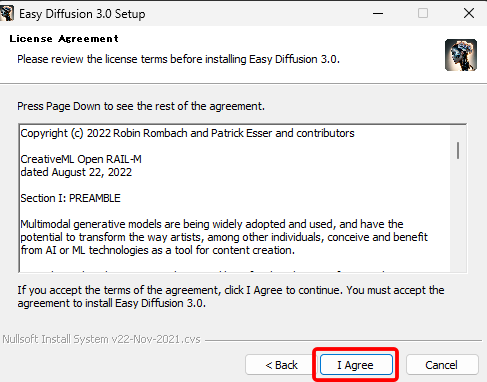
インストールフォルダを確認します。
初期設定では「C:\EasyDiffusion\」となっています。
この後、追加でモデルをダウンロードすることにもなりますので、必要であれば変更をしてください。
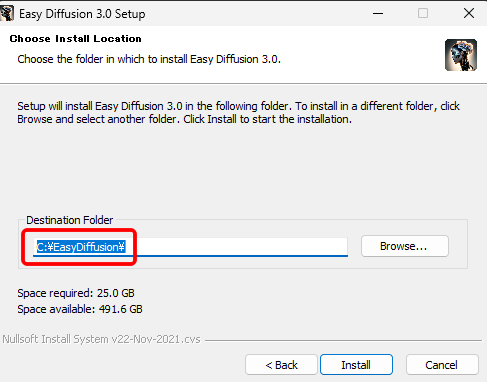
インストールが開始されます。
私の環境では1時間ほどかかりました。
気長に待ちましょう。
「Finish」をクリックします。
初回起動
起動すると、コマンドプロンプトが開きますので、閉じずに待ちます。
特に初回は、完了するまでに数分かかると思います。
ブラウザで「http://localhost:9000」が開き、使用できる状態となりました。

画像の生成
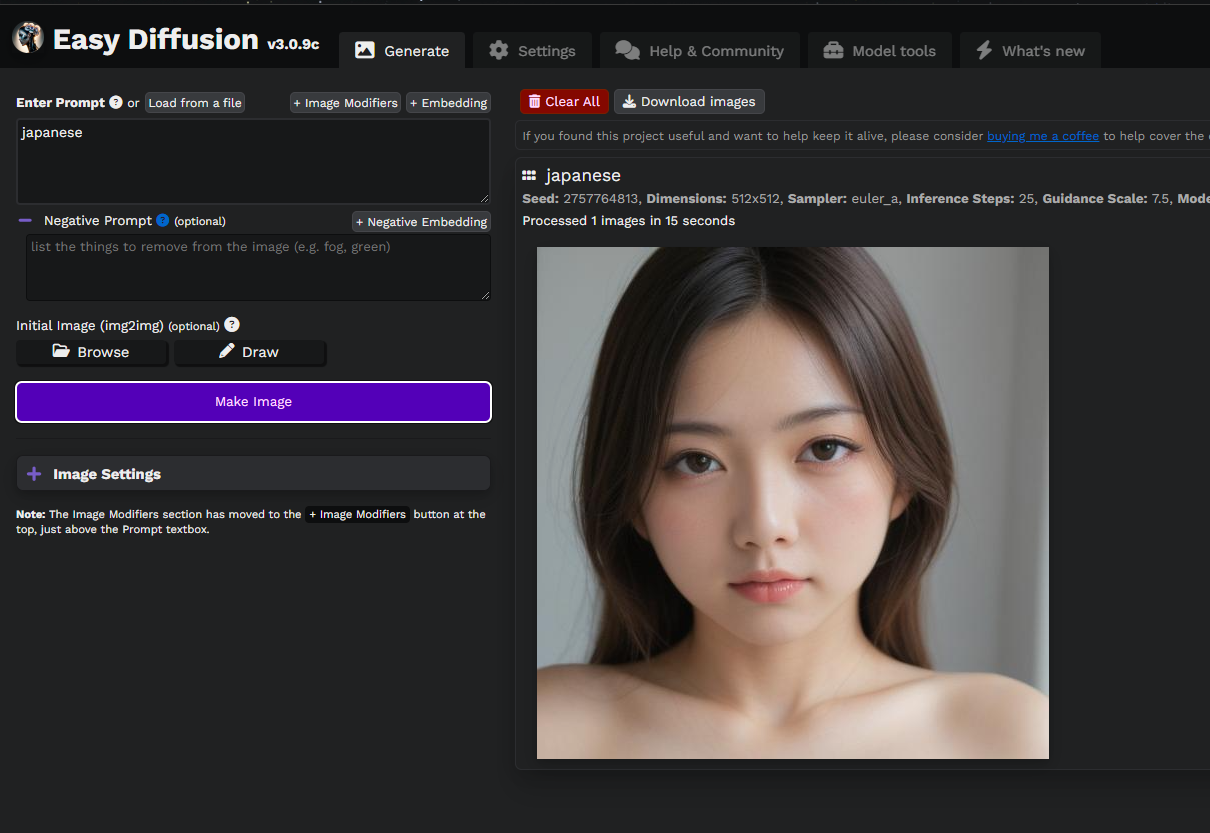
Easy Diffusionの基本的な使い方は、「プロンプト」に生成したい画像の説明を書き、「Make Image」をクリックするだけです。
テストプロンプトとして「a photograph of an astronaut riding a horse(馬に乗っている宇宙飛行士の写真)」と入っていたので、そのまま「Make Image」してみます。
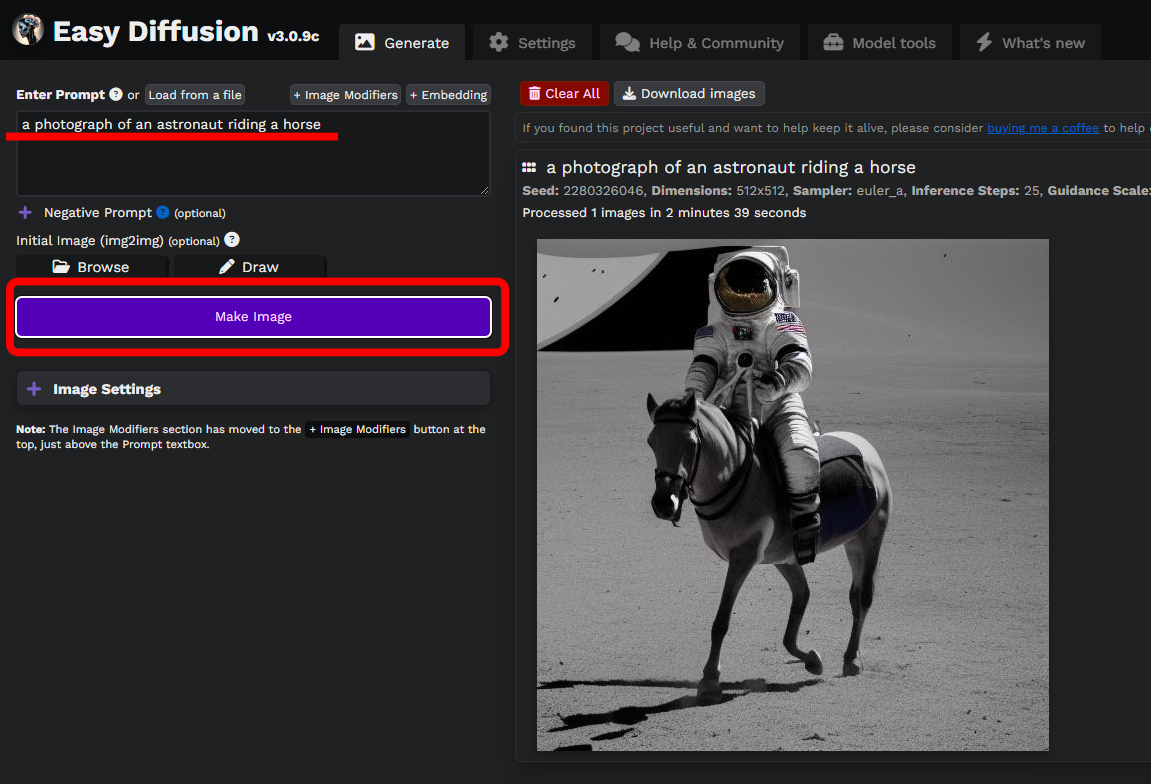
それっぽい画像が生成されましたが、よく見ると馬の脚が3本ですね⋯⋯まぁ、そんなものです。
プロンプトは、文章ではなく、短い単語をコンマで区切って入力していきます。
日本語には対応していないので、英語で入力する必要があります。
その他、特殊な文法もありますが、最初は気にしなくてよいでしょう。
既存の画像の変更
画像をゼロから生成するのではなく、既存の画像の一部を変更することもできます。
「Browse」をクリックし、PC上の画像を選択します。
傘を持った女性の画像を選択しました。
サイズが「1600 x 2024」あり、私のPC環境で実行するには時間がかかりそうです。
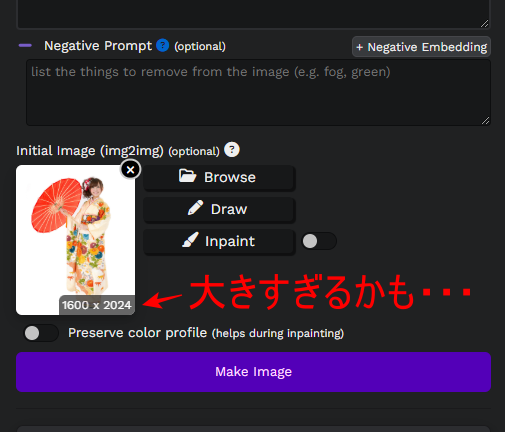
「Image Size」で「400 x 512」に変更しました。
縦横比は変えないほうがよいでしょう。

「Inpaint」をクリックします。
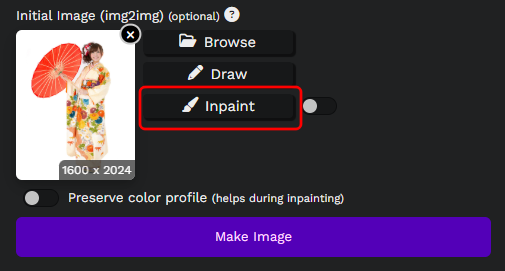
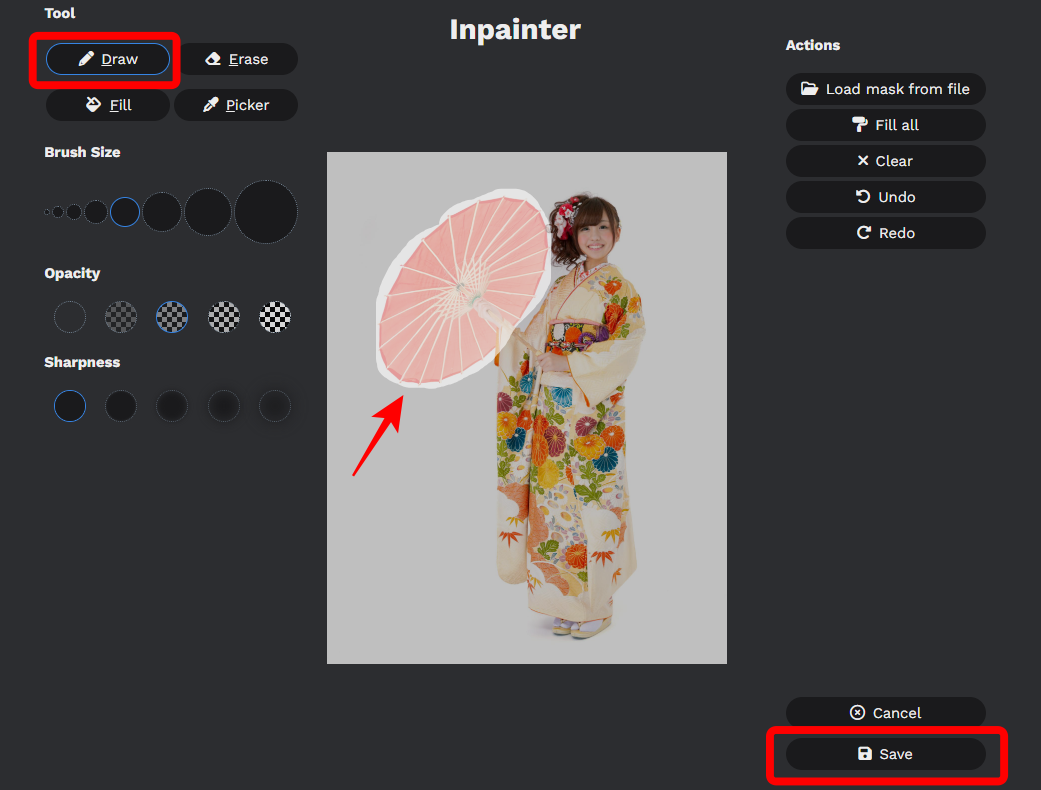
「Draw」をクリックし、変更したい箇所を塗りつぶします。
ここでは傘の領域を選択しました。
先に画像サイズを変更しておかないと、やり直すことになるのでご注意ください。
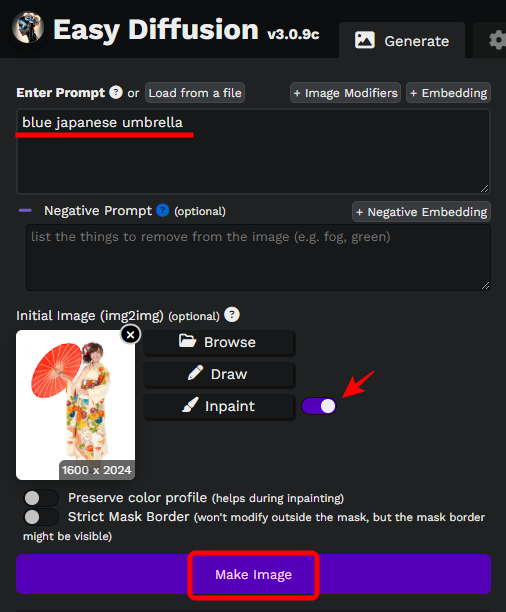
変更したい内容のプロンプトを入力します。
ここでは色を変更したいので「blue japanese umbrella」としました。
「Inpaint」にチェックが入っていることを確認し、「Make Image」をクリックします。
できあがりは、うーん⋯⋯
クオリティはともかくとして、(基本的に)選択した範囲だけが変更されることにご注目ください。

今回は31秒で生成されましたが、オリジナルの画像サイズの場合は、数分~数十分かかったと思います。
これで、プロンプトや設定を調整しながら、再作成していくという流れとなります。
モデルの追加インストール(Civitai)
Easy Diffusionには標準で「SD-v1-4(Stable Diffusion バージョン1.4)」という、2022年に公開されたモデルが入っていますが、おそらくそのクオリティには満足できないと思います。
そこで、プロンプトや設定の前に、まずは最新のモデルをダウンロードすることをおすすめします。
画像生成AIのモデルを公開しているサイトはいろいろありますが、一番有名なのがCivitaiです。
アカウント登録
Civitaiはアカウント登録をしなくても利用できますが、表示内容や、ダウンロードできるファイルに制限がかかっていので、登録することをおすすめします。
右上の「Sign In」をクリックします。
「Discord」「GitHub」「Google」「Reddit」「メール」で登録できます。
必要であれば、アカウント設定で表示内容のフィルタをご確認ください。
検索とダウンロード
「Models」を選択します。
初期設定では、「今月」の「人気順」で表示されていると思います。
AIの世界は進化が速いので、みんなの評価というのが一番アテになると思います。
「Checkpoint」と表示されているものが、ベースとなるモデルです。
「LoRA」や「VAE」などは追加機能のようなものなので、ご注意ください。

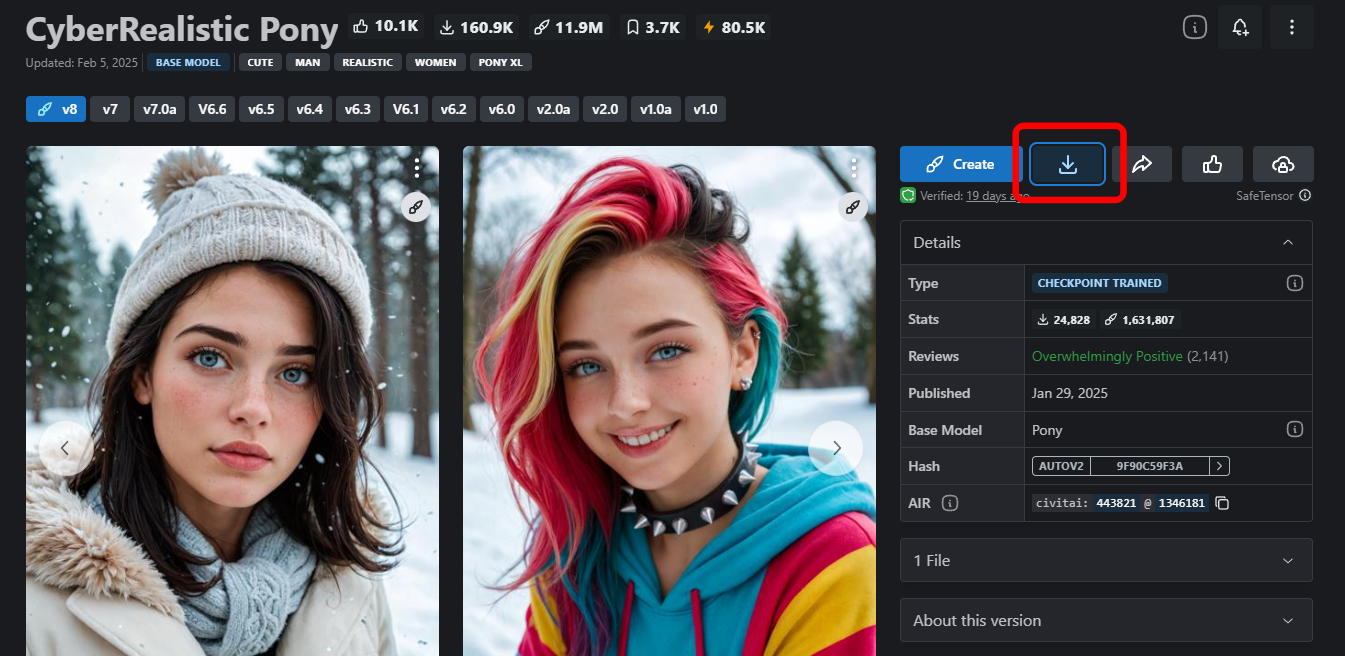
今回は評価が高かった「CyberRealistic Pony」を試してみます。
ダウンロードアイコンをクリックします。
ファイルサイズは約6.5GBです。
ダウンロードしたファイルを、インストールした「EasyDiffusion」フォルダの「models」以下に移動させます。
Checkpointの場合は「stable-diffusion」の中に入れます。
その他「LoRA」や「VAE」などは、それぞれ対応したフォルダ名の中に入れます。
間違ったフォルダに入れるとエラーとなるのでご注意ください。
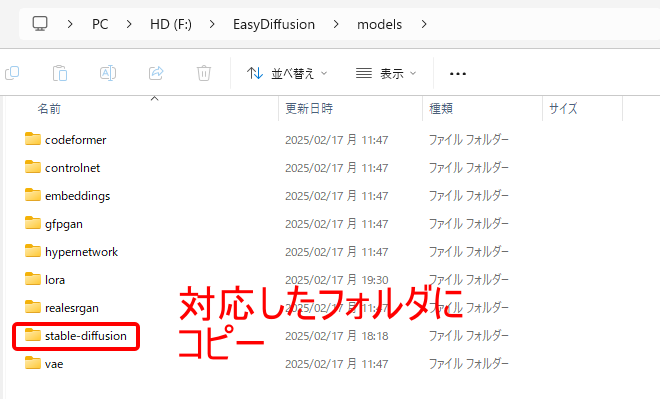
ファイルを置いたら、Easy Diffusionを再起動します。
再起動しなくてもリロードで読み込んでくれますが、失敗することもあるようなので、再起動することが推奨されています。
画像生成
モデルによっては、おすすめの設定やプロンプトが書かれているので、参考にするとよいでしょう。
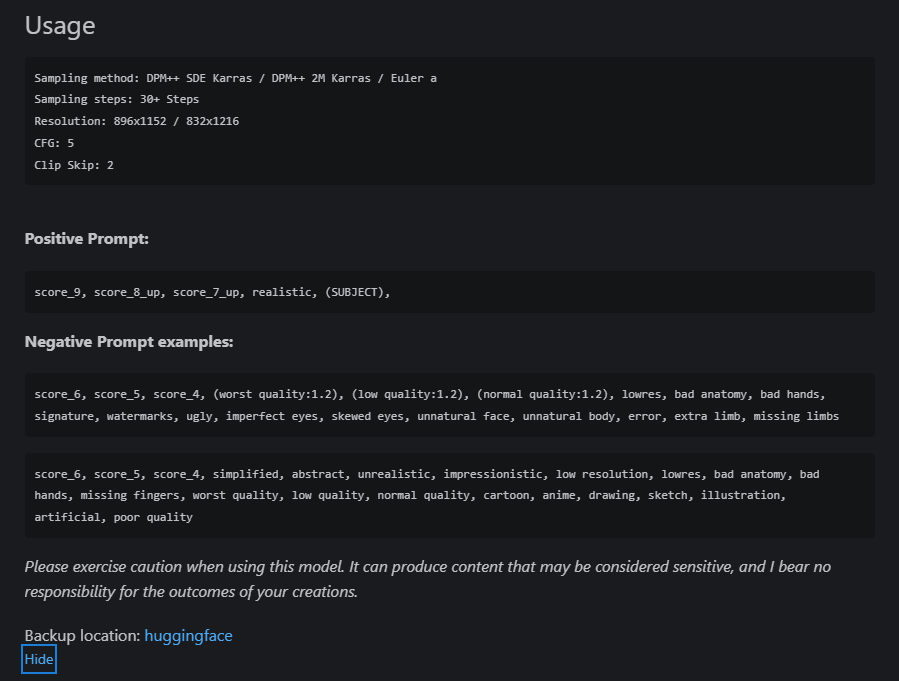
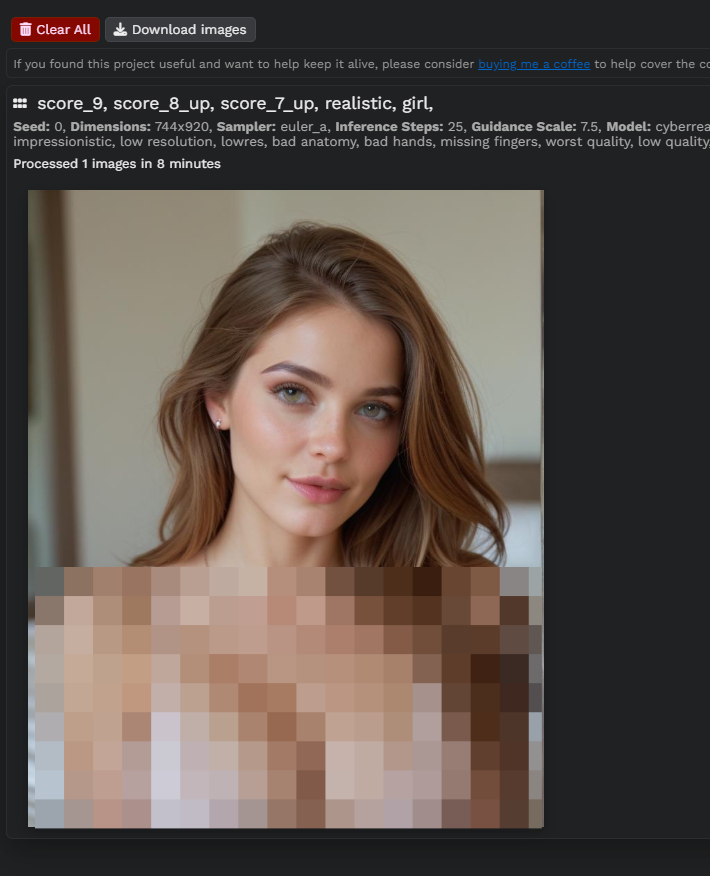
今回は、そのプロンプトに「girl」とだけ付け加えて、実行してみました。
すると、少し際どい画像が生成されたので焦りました。(服は着ているのでそのままでもいいのですが、念のためモザイク処理)
モデルによっては、センシティブ画像が生成されることもありますので、ご注意ください。
おそらくクラウドサービスの場合は制限されているので、ローカルならではかもしれません。
設定項目
画像生成の設定項目について、簡単に解説をします。
Prompt
AIに何を描いて欲しいのか伝える指示です。
短い単語で、テーマ、詳細、スタイル、フォーマットなどを指示するとよいとされています。
Nevative Prompt
生成される画像に含まれたくない要素を指示します。
「ぼやけ」「ノイズ」「不自然な手」など、品質に関する言葉が使われることが多いです。
Initial Image
生成の元となる画像です。
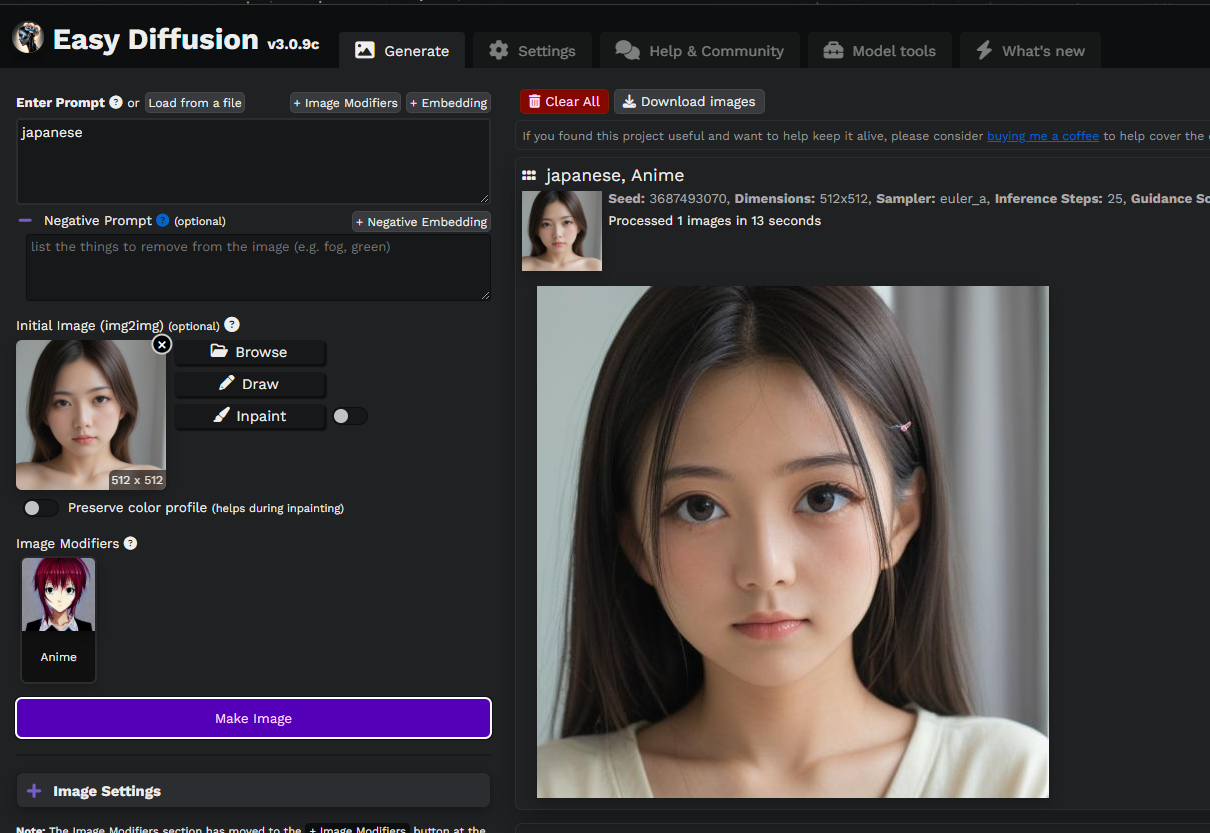
image Modifiers
「アニメ風」「水彩画」など、画像のスタイルを指示するための単語集です。
Embedding
AIに特定の単語の概念を理解させるための、小さなモデルです。
Seed
生成される画像をランダム化するための数字です。
同じ番号を使用すると、同じ画像が生成されます。
Number of images
一度に生成する画像の枚数です。
AI画像生成の基本は、数撃ちゃ当たるです。
Model
画像生成に使用する基本モデルです。
Clip Skip
プロンプトをどのように解釈するかの処理の違いです。
どのように処理されるかは、モデルにより異なります。
ControlNet Image
指定した画像に、ポーズや色調などを似せることができます。
Custom VAE
最終的な仕上がりを調整する補助モデルです。
Sampler
計算アルゴリズムの違いです。
何が良いかは試してみるしかありません。
Image Size
出力される画像サイズです。
サイズが大きいと、生成に時間がかかります。
Inference Steps
AIが補正を繰り返す回数です。
25程度が妥当とされています。
Guidance Scale(CFG)
AIがプロンプトにどれだけ厳密に従うかを決める数字です。
7.5程度が妥当とされています。
Prompt Strength
Guidance Scaleと同じように、プロンプトが与える影響力の度合いのようですが、詳細不明です。
画像生成AI一般ではなく、Easy Diffusion独自のパラメーターかもしれません。
LoRA
補助となる、サイズの小さなモデルです。
どの程度影響を与えるかを数値で指定します。
Seamless Tiling
境界に違和感がないように、隣り合った画像を生成します。
Output Format
出力される画像のファイル形式です。
「jpeg」「png」「webp」が選択でき、圧縮率(Image Quality)なども指定できます。
Enable VAE Tiling
画像を分割してVAE処理することで、VRAMの使用量を抑える機能です。
Show a live preview
レンダリング中の画像が表示されます。
Fix incorrect faces and eyes
不自然な顔を修正するアルゴリズムを選択します。
Scale up
画像の解像度を上げるアルゴリズムを選択します。
Show only the corrected/upscaled image
オフにすると、修正や拡大前の画像も表示されます。

Easy Diffusionのアンインストール
Easy Diffusionのアンインストール方法は、インストールしたEasyDiffusionフォルダを削除するだけです。
ショートカットなどを作成した場合は、手動で削除してください。
